
By Chuck Kelley1 and Marcia Gadbois
Chuck and Marcia will share a follow-up blog on best practices for database design during the week of May 12. Stay tuned to our next blog.
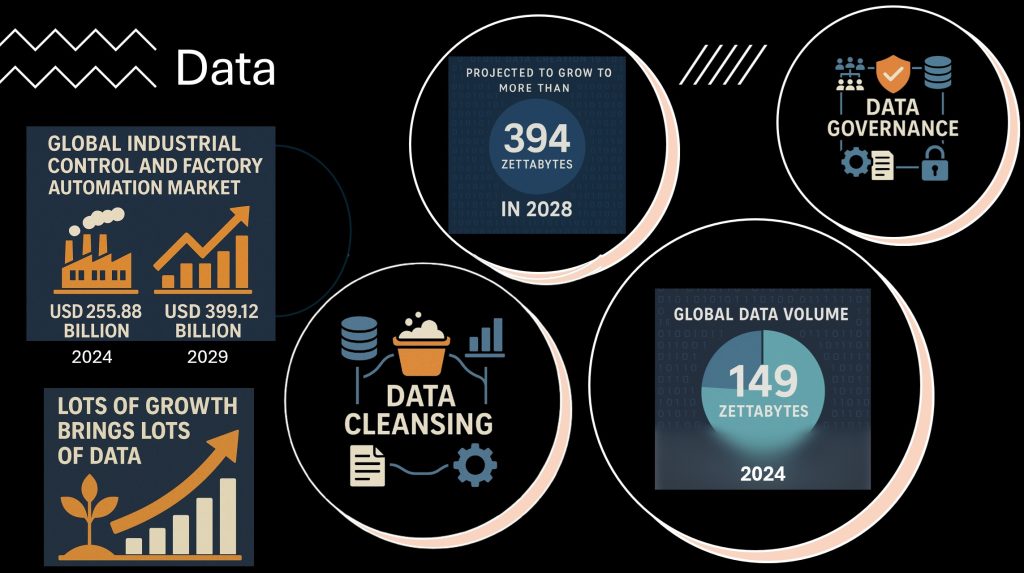
We are living in the era of data explosion. In 2024 alone, the total amount of data created, captured, copied, and consumed globally reached an astonishing 149 zettabytes, a figure projected to more than double to 394 zettabytes by 2028. For context, a single zettabyte equals a sextillion bytes, that is, a one followed by 21 zeros. This exponential growth is not just a headline statistic; it reshapes how businesses operate and innovate, especially in industrial automation.
As industrial automation accelerates, so does the volume of data it generates. A recent report from Research and Markets (March 31, 2025) estimates that the global industrial control and factory automation market, valued at USD 255.88 billion in 2024, is on track to hit USD 399.12 billion by 2029, growing at a CAGR of 9.3%. Technologies like artificial intelligence (AI) and the Internet of Things (IoT) fuel this surge, as they rely on continuous data streams to optimize processes, enhance productivity, and support smarter decision-making in manufacturing and beyond.
AI systems thrive on large, clean datasets, especially those built on machine learning and generative models. Every recommendation, predictive insight, or automated action is powered by data collected, processed, and refined in real time. Likewise, IoT devices, from smart sensors on factory floors to autonomous robots, serve as constant data generators, feeding industrial systems with valuable insights every second.
However, more data does not automatically mean better outcomes.
Enterprises must navigate this vast digital landscape with care. Data’s value is only realized when it is accurate, accessible, and actionable. That is where data governance and data cleansing come into play. Without clear governance frameworks and regular cleansing practices, organizations risk making decisions based on incomplete, inconsistent, or incorrect data.
Moreover, cloud computing has lifted previous storage limits, allowing businesses to keep more data longer. However, this also means poor data management practices can scale just as rapidly. As more companies migrate to the cloud and embrace real-time analytics, the need for disciplined and good data hygiene becomes critical.
This blog will explore managing the flood of data generated in today’s industrial environments. By focusing on the critical roles of data governance and data cleansing, we will outline essential practices to ensure your data remains a strategic asset that is accurate, compliant, and ready for analysis instead of becoming an overwhelming liability.

Where Strategy Meets Structure: How Data Governance and Cleansing Work Together
Data governance and data cleansing may seem like separate practices, but together they form a powerful foundation for reliable, usable, and compliant data. In the context of industrial automation, these two disciplines ensure that your data remains a strategic asset, ready to support decision-making, regulatory compliance, and operational excellence.
Let us explore how data governance and cleansing intersect to support key business outcomes:
1. Data Integrity
Data integrity ensures that your data is accurate, consistent, and trustworthy.
Governance establishes standards for data entry, validation, and quality control across the organization.
Data cleansing reinforces these standards by identifying and correcting inaccuracies, such as erroneous sensor readings or duplicated entries, that naturally arise over time.
2. Data Usability
For data to be valid, it must be clean, organized, and interpretable.
Governance ensures data is properly cataloged, documented, and maintained across systems and departments.
Data cleansing transforms messy, inconsistent inputs into structured, actionable formats, making generating reports, driving analytics, and powering AI/ML models easier.
3. Compliance
Regulatory compliance is essential in industries like manufacturing, energy, and pharmaceuticals.
Governance defines the rules for data handling, retention, and auditing, aligning with standards like FDA 21 CFR Part 11 or ISO certifications.
Data cleansing helps flag and remove non-compliant or outdated records that pose legal or operational risks.
To learn more about the features in ADISRA SmartView that support FDA 21 CFR Part 11 compliance, check out our video and whitepaper. They provide valuable insights into how you can build secure, compliant applications with ease.
4. Data Security
Safeguarding sensitive information starts with clear access policies and continues through secure data handling practices.
Governance defines who can access what data, under what conditions, and ensures security policies are enforced.
Data cleansing supports security by identifying and eliminating unnecessary or sensitive data that should not be retained or exposed.
5. Performance
In a world of growing data volumes, maintaining system performance is essential.
Governance helps manage data growth with clear retention and archival policies.
Data cleansing improves efficiency by removing duplicate, irrelevant, or outdated records that can slow down processing and analysis.
In today’s data-driven industrial landscape, governance and cleansing must go hand in hand. A unified approach ensures that your data flows with purpose, accurately, securely, and is ready to drive results.
What is Data Cleansing in Industrial Automation?
One of the biggest issues facing industrial automation, as well as all automation, is the issue of data cleansing. If your front-end systems (PLC, SCADA, POS) are not collecting accurate data, you need to put in place a data cleansing environment. Data cleansing is about preparing data to be consumed by systems downstream, such as predictive models, analytics packages, or management information systems (MIS), to name a few.
Data cleansing ensures accuracy so that the downstream systems have good data arriving to help the organization become more productive. For example, there are surveys that show that data scientists spend 60 – 80 percent of their time cleaning data rather than doing their “real” job – finding new trends, training models with good data, and enhancing algorithms. When presented with cleansed data, that will reveal an excellent return on investment (ROI), allowing them to do what they were really hired to do for the majority of their time.
What is involved in data cleansing? The answer to this question depends on what your front-end systems are. I remember working with a company that did not like to make the plant floor employees punch in their correct employee number before doing any work. They hired managers to make changes to the data after it was collected to make sure it was correct. Also, they had assigned all of the plant equipment the equivalent of employee numbers in the system. An employee punched in the number of a milling machine, and it was not caught by the manager. So the data showed that this milling machine went on a trip to attend a training class and then returned to teach the engineers what it had learned.
Organizations need to put processes in place (instead of using human capital) to maintain the accuracy of the data. In the example above, a mere check of the data when the employee put in the employee ID could have reduced expenses and maintained a more accurate representation of what was happening on the floor.
What is data cleansing? At the highest definition, it could be described as a processing step that transforms the data into a more consumable and available format. That processing step can be as simple as removing duplicate data, automating the correction of errors, or standardizing formats that will be used by the consumers of the data (data scientists, predictive models, analytics packages). It should also include filtering noise from the sensor data, correcting timestamp mismatches, and aggregation. The process should also include the ability to connect to outside sources of data, like Historians, to supplement your own internal data.
As you can guess, data cleansing is a time-consuming process. However, it is a critical process that enables organizations to move to AI and predictive applications to transform their industry.

Data Governance: Trust, Security, and Accountability
One of the biggest inhibitors of a strong data environment is not technical. It is company politics. The inability to get teams to work collaboratively is one of the reasons why so many projects fail to reach their full potential. Because of this, organizations have created Data Governance Boards to help (but it does not always) alleviate the issue. The Data Governance Board’s overarching job is to ensure data is useful, adds value, is credible, and accessible to the people and processes that need that data.
What is data governance? Data governance is a set of policies, roles, and responsibilities that are set in place to ensure data quality and compliance for the organization. All stakeholders need to participate in the process, and it is mostly driven by the business community, not by technology. There needs to be agreement on what terminology means (are measurements in inches or centimeters so they are comparable without calculations, who is responsible for a particular piece of data (data stewardship), and what are the valid values for that data). When all the decisions are made, it is up to technology to implement them. Technology is part of the data governance process by guiding what is possible. Some requests from the business can cause an astronomical increase in the cost of implementing technology and cause failure in data governance.
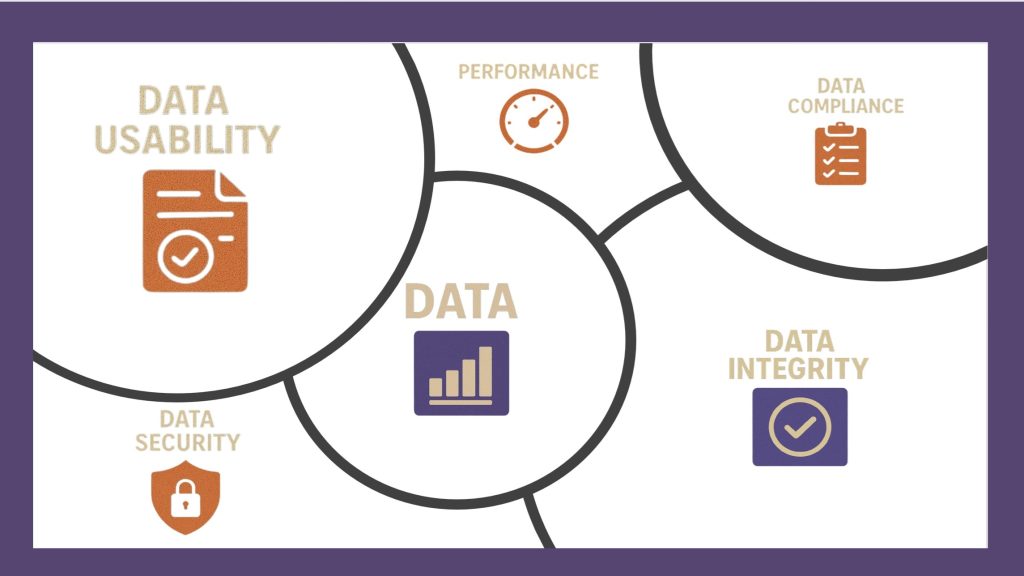
What are the key pillars of data governance?
- Data Quality
- Data Compliance
- Data Privacy and Security
- Data Usability
- Data Availability
Data Quality
Data quality is concerned with the accuracy, consistency, completeness, and timeliness of each piece of data. In my previous example above, there was no agreement on the quality of data, so anyone could just put in any data. There was no accuracy or consistency, which required managers to be hired to modify the data to be complete and timely. Data quality is the responsibility of the data steward(s). If new data needs to be introduced, the data steward(s) responsible for the specific piece of data need to agree on what it means and what the valid values are.
Data Compliance
Data compliance is concerned with the policies, standards, legal, and regulatory requirements. There is a broad set of rules and regulations, both inside and outside of the organization, that will apply to some pieces of data. They can vary by region and industry. The data governance process needs to understand those rules and regulations to make sure that the organization can pass compliance audits.
Data Privacy and Security
Data privacy and security are concerned with who or what can see a piece of data and how it is to be protected. Would you want the whole company to be able to see the number of items being manufactured that failed to comply with the design? Well, maybe if the failure rate was .01%, but what about 40%? Would you want every piece of data to be available to the public? Data privacy details who (person or group) has access to what piece of data. With the whole world watching, you probably do not want to see data breaches of your organization all over the press. Security is about protecting data by mitigating security risks. Some of the security risks include unauthorized access and data breaches. Different methods can be used to secure the data. The Data Governance Board understands the risks and processes and defines what needs to be done.
Data Usability
Data usability is concerned with making data easily accessible, understandable, and usable to increase the ability to make data-driven decisions. How usable is your data if one measurement is in inches and the other is in millimeters? The user of the data would have to remember to convert. The same is true for degrees in Celsius and Fahrenheit. The data steward(s) need to come to an agreement, and everyone needs to use the same measurement.
Data Availability
Data availability is concerned with the accessibility of data when needed. Having stakeholders who need the data have to search to find the required data, do any required formatting, transform the data into the measurement that is required, and then saving it in the layout required by application they are using (spreadsheets, analytics package, model) is not the best use of the stakeholders time. Having the data already cleansed, prepared, and placed in a known location is the end goal of data availability.
Putting it all together
Data governance ensures the consistency and trust of data that is available within the organization. It is very important in regulated industries (dealing with the FDA, food safety, and energy reporting), but it is also important to the stakeholders within the organization.
The output of the Data Governance Board should be accessible to whoever needs that information as soon as they need it. Data cataloging and metadata (data about data) management is a part of this. There are platforms available to help you create proper access to this data so that the data is accessible and available to those who need it.

Turning Strategy into Action with ADISRA
At ADISRA, we understand that effective data governance and cleansing are not just IT concerns; they are foundational to driving better decisions and smarter automation. That is why our software solutions are designed to help you implement and sustain these best practices:
ADISRA SmartView empowers users to create HMI/SCADA applications that enforce data entry standards, apply real-time validation rules, and manage data access through role-based security. With built-in support for alarms, trends, and event tracking, ADISRA SmartView helps maintain data integrity from the edge to the enterprise.
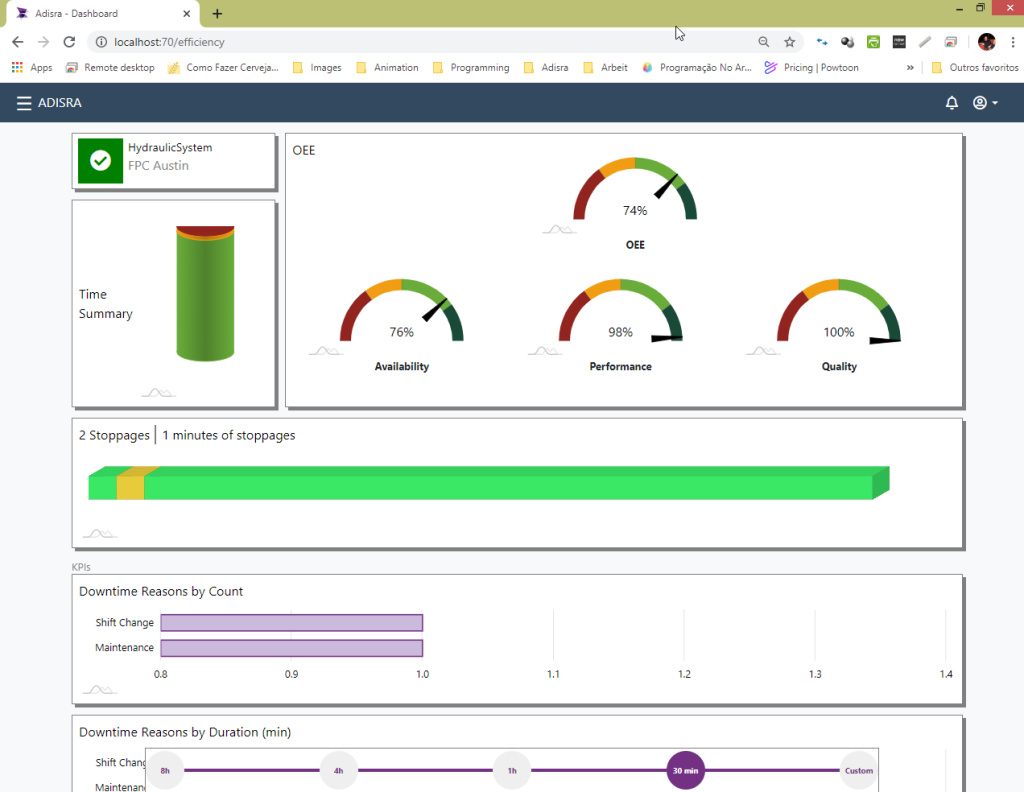
InsightView, our analytics platform, relies on clean and well-governed data to provide accurate OEE metrics, KPIs, and production insights. It includes tools for data normalization and supports seamless integration with third-party sources, ensuring consistency across the board.
Together, these tools form a powerful ecosystem that supports your data strategy from collection and cleansing to governance and actionable insight.
Experience ADISRA SmartView by downloading a software trial from our website here.
Interested in trying out InsightView? Request a temporary account on our website here.
Conclusion: From Raw Data to Real Value
As industrial automation continues to evolve, data is no longer a byproduct; it is a competitive advantage. But to unlock its full potential, organizations must go beyond just collecting information. Clean, governed, and well-structured data is the backbone of operational excellence, compliance, and digital transformation.
Data governance ensures that your data is trustworthy, consistent, and aligned with business goals. Data cleansing transforms chaotic or incorrect inputs into valuable insights. Together, these practices empower teams to make faster, smarter decisions with confidence.
At ADISRA, we are committed to helping you succeed in this data-driven world. Whether you are building intelligent HMI/SCADA systems with ADISRA SmartView or extracting real-time performance insights through InsightView, our tools are designed to support your governance and cleansing strategies every step of the way.
In the end, the difference between overwhelmed and optimized comes down to how you manage your data. With the right processes and the right tools, you can turn a flood of information into a strategic asset that drives measurable results.
Join us for our upcoming webinar on May 22nd at 9:30 a.m. CDT! We will cover how to communicate with third-party systems such as ML vision systems, Java modules, relational databases, and Historians. Do not miss it—register today!
- Chuck Kelley is a consultant, computer architect, and internationally recognized expert in data technology. With over 40 years of experience, he has played a key role in designing and implementing operational systems, data stores, data warehouses, and data lakes. Chuck is the co-author of Rdb/VMS: Developing the Data Warehouse with Bill Inmon and has contributed to four books on data warehousing. His insights have been featured in numerous industry publications, where he shares his expertise on data architecture and enterprise data strategies. Chuck’s passion lies in ensuring that the right data is delivered in the right format to the right person at the right time ↩︎

Marcia Gadbois is General Manager and President of ADISRA. She is a seasoned entrepreneur and technology executive with over 34 years of experience in the software industry. She has successfully led a startup from inception to a profitable exit and has held multiple senior leadership roles in business development, strategy, marketing, sales, and competitive intelligence.
Before joining ADISRA, Marcia served as President of InduSoft, where she played a pivotal role in its growth and eventual acquisition by Invensys. Her extensive background spans diverse technology domains including artificial intelligence, operating systems, rapid application development, output management, databases, middleware, directory services, data recovery, and industrial automation.
Marcia is a contributing author of the book Client/Server Programming with RPC and DCE and has published numerous articles and whitepapers throughout her career. She holds a BS in Management Information Systems and Computer Science from Bowling Green State University and an Executive MBA from the University of New Hampshire.

ADISRA®, ADISRA’s logo, InsightView®, and KnowledgeView® are registered trademarks of ADISRA, LLC.
Copyright © 2025 ADISRA, LLC. All Rights Reserved.