
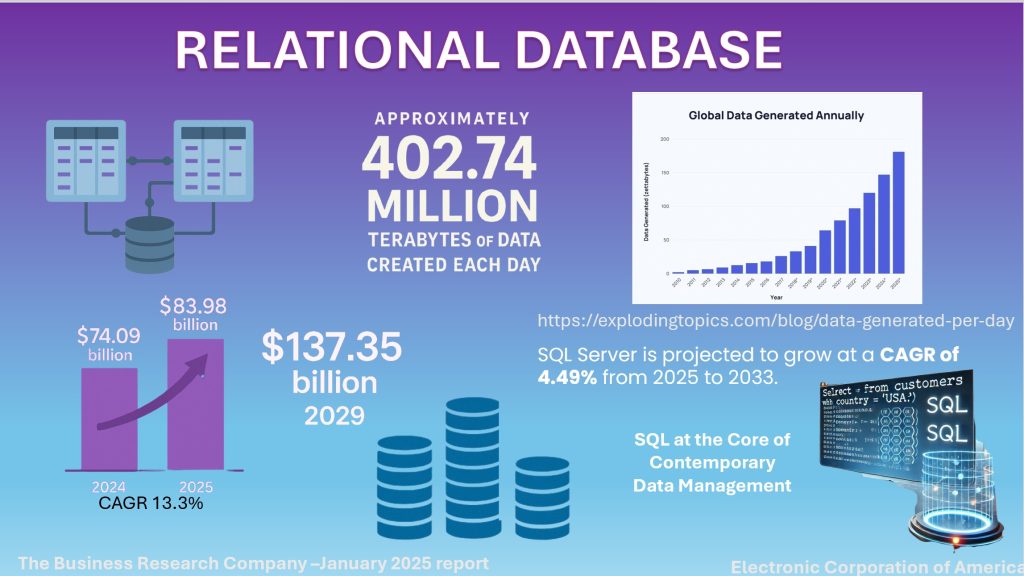
In a world where data is growing at a staggering rate —over 400 million terabytes per day —the difference between operational chaos and actionable insight often comes down to one thing: how well your data is organized and accessed.
Nowhere is this more critical than in industrial automation, where data flows continuously from sensors, programmable logic controllers (PLCs), edge devices, and enterprise systems. This data can easily become a burden instead of an asset without a thoughtful and scalable architecture.
Enter relational databases, the enduring backbone of enterprise information management. The global relational database market is projected to reach $83.98 billion by 2025, driven by the growth of IoT, cloud platforms, and edge computing.
But using a database is not enough. Great automation outcomes demand great database design.
In a previous post, we discussed the risks associated with poor data quality and the importance of governance and data cleansing. In this blog, co-authored with database expert Chuck Kelley, we shift the focus to building better databases from the ground up, highlighting proven best practices for design that ensure your data stays clean, secure, scalable, and ready to serve your organization’s goals.
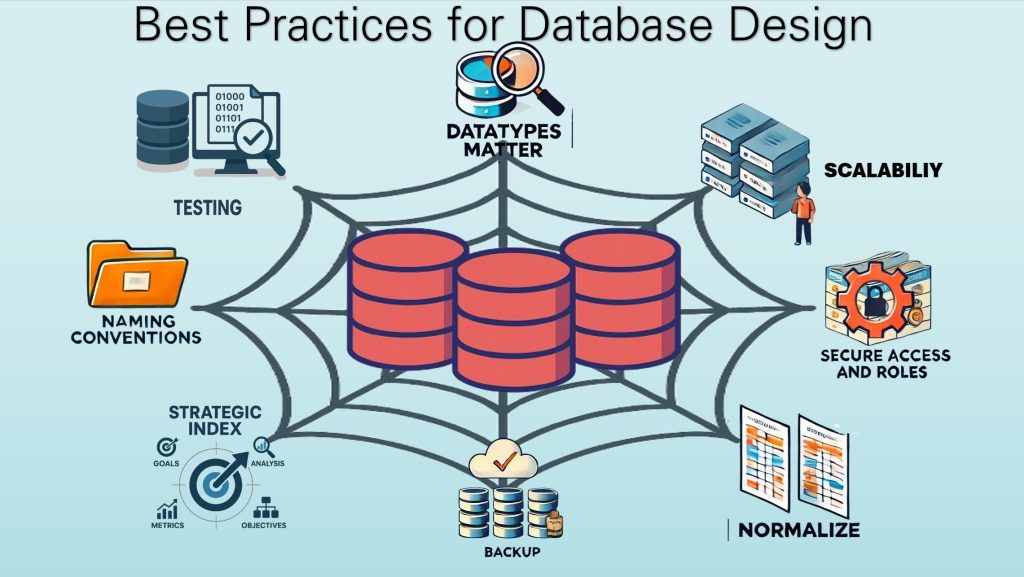
Why Database Design Matters
Before designing any system, ask: How will the data be used?
– Operational systems (e.g., shop floor machines) require highly normalized data for quick write performance and minimal redundancy.
– Analytical systems need denormalized structures to support large-volume reads, aggregations, and trend analysis.
Understanding this distinction upfront shapes everything from table structure to indexing strategy.
Best practices for a good database design – Written by Chuck Kelley
We discussed some of the consequences of allowing bad data into your data and why it is important to put data governance and a data cleansing process in place in our last blog, which you can access here. Now, let us discuss some best practices while doing your database design.
Database design not only includes defining tables and columns (in relational databases), but also security, testing, backup/restore, and documentation of everything that is done to keep your data clean, safe, and secure, and accessible by the correct stakeholder(s).
Why does database design matter?
The most important design consideration, in my opinion, is the use of the data. In the operational world, you would like to have more normalized data. Operational data is what you would find on the plant floor, capturing what a specific machine is doing. It includes data that is captured when your customers place orders. In real-world scenarios, these are defined as 3 read, 2 write transactions. It does not imply only 3 reads and 2 write transactions, but is more about the processing of the data. Data that is written needs to be captured quickly and done in short transactions. Analytic data is defined as read a million and aggregated. Again, it does not mean that you are reading 1 million rows of data, but that you are reading and aggregating a large amount of data to provide to the stakeholder.
The design of those systems is drastically different. It is important that your design considers its intended use.
Use Clear, Consistent Naming Conventions
The output of the data governance process should be clear and consistent names of the data that will be stored. As some of these names can be quite long, it might be wise to create a Naming Conventions document that discusses the shortening of data names, how the data name is defined, etc.
For example, some organizations document that all column names begin with the data type (e.g., int, char), while others document that all column names end with the data type.
Whatever your organization uses, make sure that it is documented and that your data modeling tool can convert from logical to physical model using those conventions. There are many other options that can be considered, but this blog is about the best practices more than actual procedure.
All of this information should be stored in the data governance data catalog and metadata management repository.
Datatypes matter
When designing the database, datatypes matter. Everything is about trade-offs. If you have a column that will only hold the values of 0, 1, 2, or 3. In character datatype, it will take 1 byte. In a tiny int, it will take 1 byte. In a small int, it will take 2 bytes. An integer will take 4 bytes. Therefore, some will say that you can use character, rather than tiny int (assuming your database of choice has a tiny int), because it is easier to deal with. However, if you are querying the column using
Where columnName = 1
which a lot of programmers/dbas will do, there is an implicit conversion of the value of 1 to the character ‘1’. Therefore, you will be using more compute. If there are 10 million rows (with no index on columnName, that conversion will occur 10 million times for each query. That’s a lot of CPU cycles for no clear value.
Another issue with the above strategy is that over time, you might have values go larger than 9, so that you would then have to increase the character size from 1 to something else. This may cause row splitting and degrade performance.
It is important to understand how the database that you choose handles these situations.
Normalize Where Appropriate
Every Database Administration/Data Designer (DBA/Data Modeler) understands the trade-offs of normalization. Normalization is the process of normal forms (named 1st, 2nd, 3rd, 4th, etc.) that is used to reduce redundancy and improve integrity by reducing data anomalies. For more information, research Edgar Codd and Chris Date. At this time, I think there are 11 normal forms. However, most databases get to 3rd (or 3 and 1/2) normal form.
The biggest issue is the trade-off of performance vs data anomalies created by redundancy. Here is an aspect of understanding how your database system work. How does your database system process joins? The further you go in normal forms, the more joins will need to occur. Some databases perform joins well and others not so well.
The normalization process is really important in operational systems. In analytic systems, it is typically less normalized because joining multi-million row tables is quite time-consuming in both I/O and CPU.
So, the question goes back to the section on why database design matters. As an organization, you want to have the right data in the right format at the right time for every stakeholder.
Index Strategically
Indexes have 2 purposes in life — speed up retrieval and slow down updates. As with everything else with databases, this is a matter of trade-offs. In operational systems, slowing down updates is not a good thing to do. Therefore, you are most likely trying to pick the fewest number of indexes that balance fast updating (insert, update, delete) of the data. Therefore, thinking about how each index will affect the processing is critical.
In analytical systems, speeding up retrievals is the most important aspect. Generally, you index a lot more. However, strategically indexing still applies because when you load the new data into the database, having lots of indexes will really slow down that process, and there is (almost) never a system that has enough time.
Indexing is also used in data integrity. The relationship between data is just as important as any piece of information. What good is the value 23? What does 23 mean? It could mean that 23 is the temperature at which some liquids become solid. It could mean something costs 23 dollars. It could be talking about the 23rd state of the United States alphabetically sorted. So, it is the relationship of data that becomes important. This goes back to your data governance. Defining the relationships of the data and making sure the systems adhere to those relationships will ensure the integrity of the data is compliant with your data governance.
Design for Scalability and Archiving, then Test
Have you ever made a design, loaded a few hundred rows, and everything ran perfectly? However, during testing, everything was slow. What works for a few rows may not work for a few million rows. Therefore, you need to test your database with real data volumes. Real data volumes give you information about how much memory and disk I/O is required. The few hundred rows will fit in memory, but a few million rows may not.
In operational systems, it is wise not to store 100 years’ worth of data in your database. There needs to be a good archiving process designed to alleviate the older data. However, analytical systems need that data. However, as data ages, what becomes more important is the aggregates more than the raw data. So, an archival system needs to be put in place for both operational and analytical databases.
Designing for scalability and archiving should not be an afterthought. It should be part of the normal process of every database that is being designed. Then the applications need to be tested using real data volumes. While it is true, there is a cost associated with testing with real data volumes, there is also a cost of not testing with real data volumes. That cost includes being slow (or down) and not being able to capture the data has a real cost as well – loss of revenue.
Secure Access and Roles
During the data governance process, security and access should have been separated into different roles. When designing the database, access and roles need to be considered. Some database systems allow for column-level roles, but most do not. Therefore, separating the data may become important to provide security for the data.
Having a wide-open database is how data breaches occur. By defining roles with the proper privileges, you can alleviate some (but not all) improper access. Some individuals with proper access may engage in nefarious activities.
Document Your Schema
When I was younger, I disliked documenting my databases. The databases were self-documenting because I had put all the information in the data model. The table names and column names were self-documenting. What else do people need? However, who has access to the data model?
It became clear as I aged that documenting my assumptions, how the database implemented the requirements from the data governance team, how security worked, and more information about the data related to other data needed to be documented.
This documentation will feed back to your data governance data catalog and metadata management system.
Backup and test your backup (restore).
If you have never tested your backup by restoring it, you don’t have a backup. You have a disaster waiting to happen.
I can’t say that loud enough!
Have you designed your backup strategy? How often do I do a full backup? How long does it take to back up? It will take a long time to restore. What are my requirements for restoring? Some operational systems have short down time requirements. Therefore, knowing how long a restore will take helps you design your backup strategy.
So remember, design your strategy and test it.
Lastly
What was discussed was mostly around relational data. However, sometimes there should be consideration of time series data. When operational systems only send data based on when the last change occurred (temperature change x degrees, volume increase or decrease x milliliters), being able to query and see what the temperature and volume were at a particular time of day is quite hard (although not impossible) and time-consuming. Using time series data in your database may be needed. Look for databases that have time series extensions or are built specifically for time series. The design considerations still apply to time series data.
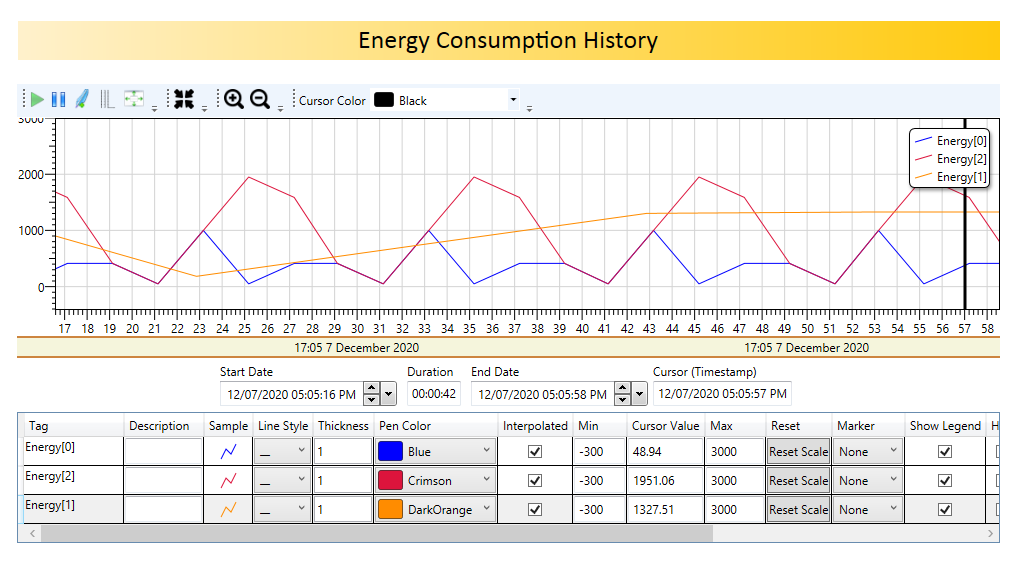
The Smart Automation Advantage with Relational Database and ADISRA SmartView
SQL has long been a foundational tool in industrial automation, but in today’s data-saturated world, it is no longer just working behind the scenes. Structured Query Language (SQL) is now front and center as a strategic asset for organizations. Your data becomes a competitive asset when paired with modern SCADA/HMI solutions like ADISRA SmartView.
Structured Query Language (SQL) is a specialized programming language used to manage and manipulate data within a relational database, where information is organized into tables consisting of rows and columns. These tables capture both the data and the relationships between data points. With SQL, users can perform a wide range of operations, including inserting, updating, deleting, querying, and retrieving data. Additionally, SQL is essential for maintaining database integrity and optimizing performance, ensuring that systems remain efficient and responsive as data grows.
With the explosion of real-time data from sensors, PLCs, and edge devices, your database is more than a support system; it is the central nervous system of your operation. When designed with best practices, an SQL-based architecture can streamline processes, reveal hidden insights, and drive smarter decision-making across your enterprise.
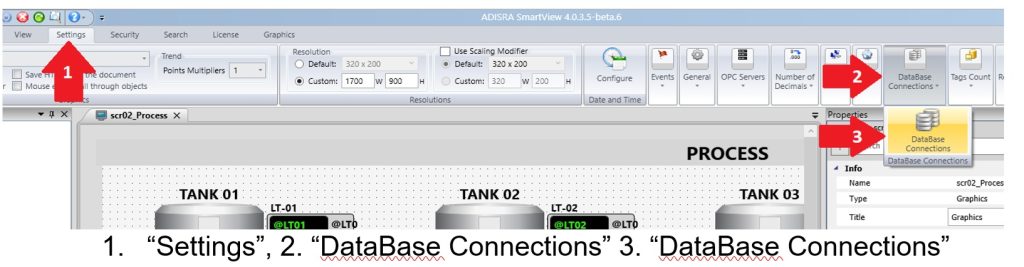
ADISRA SmartView harnesses this power by offering a proprietary database and out-of-the-box connectivity to the most widely used relational databases such as SQL Server, MySQL, PostgreSQL, SQLite, Oracle, and Microsoft Access. It also integrates with industrial historians like Open Automation Software Historian, giving you the freedom to manage your data the way that best fits your needs.
Tightly integrating SCADA and HMI systems with relational databases brings new levels of agility to your operations. From real-time monitoring to historical trend analysis and dynamic reporting, your data becomes more actionable, more accessible, and more impactful.
And with support for open standards such as SQL, OPC UA, MQTT, and web services, ADISRA SmartView lets you connect and scale effortlessly, whether you are modernizing a legacy system or building a future-ready smart factory.
Want to see it in action? Explore how easy it is to connect ADISRA SmartView to external databases with this video, this whitepaper, or this interactive demo. Do you want to try ADISRA SmartView for yourself? You can download ADISRA SmartView here.
Conclusion: Build It Right from the Start
In industrial automation, poorly designed databases are like faulty wiring in a control panel, unseen until something breaks. But great design creates clarity, speed, and confidence. By adopting these best practices and tools like ADISRA SmartView, you move from reactive to proactive, from data chaos to operational clarity.
Your competitive edge begins with smart design, powered by SQL, backed by governance, and amplified by ADISRA.
Try ADISRA SmartView today by downloading a trial package here.
ADISRA®, ADISRA’S logo, InsightView®, and KnowledgeView® are registered trademarks of ADISRA, LLC.
© 2025 ADISRA, LLC. All Rights Reserved.