By Chuck Kelley and Marcia Gadbois
In last week’s blog, we explored the foundational architectures behind data storage and the benefits of various architectures. This week, we continue our journey from raw data to actionable insights by exploring how to extract, transform, and load (ETL) data for meaningful use, particularly in industrial automation.

The global ETL market reflects just how critical this process has become. Valued at USD 7.62 billion in 2024, it is projected to reach USD 22.86 billion by 2032, growing at a CAGR of 14.80%. This growth is fueled by several converging factors: the increasing demand for data-driven decision-making, the widespread adoption of cloud technologies, the growing complexity of data ecosystems, and the urgent need to unify data from disparate sources.
Today’s industrial environments span on-premises systems, edge devices, and cloud services. In these distributed and dynamic ecosystems, simply moving data from point A to point B is not enough. Modern ETL solutions must be scalable, flexible, and intelligent, enabling real-time processing, reducing latency, and improving overall data quality.
ETL strategies are also being transformed by AI and machine learning. These technologies are ushering in a new era of automation, where intelligent tools can detect anomalies, recommend transformations, and fill in missing values with minimal human intervention. As a result, organizations benefit from higher productivity, enhanced data consistency, and better decision support.
In this blog, we will explore modern ETL strategies and architectures, including:
• Columnar and edge databases
• Cloud-based ETL and ELT
• Event-driven and microservices-based designs
• AI-powered ETL
Whether you are modernizing a legacy system or designing a future-ready data environment from the ground up, these strategies will help you unlock the full value of your industrial data.
To implement these modern ETL strategies effectively, choosing the right data storage structure is essential. Different types of databases are better suited for different workloads, especially when it comes to handling high volumes of industrial data. One such storage model, particularly well-suited for analytics and high-performance querying, is the columnar database.

Columnar Databases
Unlike traditional relational databases that store data in rows, columnar databases store data by columns. This architecture dramatically improves query performance when only a few specific data points are needed, making it ideal for analytical workloads where full row access is not required. Instead of scanning entire rows, the system can read just the relevant columns, reducing processing time and resource usage.
For example, in industrial automation, if you are analyzing energy usage trends across multiple facilities and only need two or three data fields out of a dataset with dozens of columns, a columnar database can deliver results faster and more efficiently than a row-based system.
However, it is important to note that columnar databases are optimized for read-heavy analytical operations, not for transactional systems like real-time control processes.
Some examples of columnar databases are:
- Amazon Redshift
- Google BigQuery
- Vertica
- Snowflake
Advantages of Column-Oriented Databases
Columnar databases offer several performance and scalability benefits, especially for analytical workloads:
Scalability: Columnar databases are designed for massively parallel processing (MPP), allowing multiple processors to work on the same dataset simultaneously. This makes them ideal for big data environments that require horizontal scaling.
Compression: Because data is stored in columns with similar data types, columnar databases often achieve high compression ratios, reducing storage requirements and improving I/O performance.
High Query Performance: Columnar databases are optimized for fast read operations, with minimal load times. Since queries can target only the relevant columns, they return results much faster than row-based databases in analytical scenarios.
Efficient Aggregation: Aggregating data is a common operation in analytics, and columnar databases excel at scanning and aggregating large volumes of columnar data. By reading only the required columns, they minimize resource usage and improve speed.
Disadvantages of Column-Oriented Databases: While powerful for analytics, columnar databases do have limitations, particularly when it comes to real-time processing and data modification:
Not Ideal for Transactional Processing: As mentioned earlier, columnar databases are not well-suited for real-time control or high-frequency transactional updates. While they can analyze transactions effectively, they struggle to handle frequent inserts or updates. A common solution is to use a hybrid approach: a relational database for operational data and a columnar database for analytics.
Inefficient Incremental Data Loads: Loading and updating data can be less efficient in columnar systems. To update specific values, the database may need to scan the entire column to find relevant rows and then scan again to overwrite the modified data, which can slow down the ETL process.
Security Considerations: Some columnar databases may be slightly more vulnerable to security risks, especially when compression techniques interfere with encryption protocols. A good mitigation strategy is to store sensitive or regulated data in encrypted relational databases, while using columnar databases for less sensitive analytics workloads.
Edge Databases
As industrial systems become more distributed, with sensors and devices generating vast amounts of data at the source, the need for localized data handling is increasing. This is where edge databases come into play.
An edge database is designed to store and process data close to where it is generated, at the edge of the network, such as on a machine, sensor, or local controller. This approach minimizes latency, reduces reliance on constant cloud connectivity, and allows for faster, more responsive data interactions.
Data is created, stored, and used in various contexts. Computing is more centralized. So, the idea of edge databases is to store the data in the most efficient way as close to the process as possible and then move the data as needed to where it is needed. For example, machines create data. That data can be stored locally on that machine and then periodically (with varying intervals for each organization and data type) transferred to regional servers for ingestion into the rest of the process.
For example, a machine in a factory may collect temperature, vibration, and pressure data. Instead of constantly sending this raw data to a central server or cloud, it can be stored and analyzed locally using an edge database. Critical thresholds or anomalies can be flagged in real-time, while summary data or events can be periodically transmitted to a central system for further analysis.
Benefits of Edge Databases
Low Latency: By keeping data local, edge databases provide near-instantaneous access, which is crucial for time-sensitive applications like process control or machine diagnostics.
Reduced Bandwidth Usage: Instead of transmitting all raw data to the cloud or central servers, edge databases allow selective data transfers, lowering network congestion and costs.
Increased Resilience: Edge databases can continue to operate during connectivity interruptions, ensuring uninterrupted data logging and decision-making at the edge.
Real-Time Decision Making: When data is available locally, automation systems can react quickly, triggering alarms, shutting down machines, or adjusting parameters without needing a central server or cloud instructions.
Considerations
While edge databases provide numerous advantages, they also come with challenges:
Limited Resources: Devices at the edge may have limited processing power, memory, and storage, which can constrain database performance and capacity.
Data Synchronization: Ensuring accurate and secure synchronization between edge systems and central databases can be complex, especially in environments with intermittent connectivity.
Security: Edge devices can be more physically vulnerable or exposed to cyber threats. Proper authentication, encryption, and updating mechanisms are essential.
When evaluating these various database architectures, it is important to use the right type of database for the right purposes. With the right database structures in place, whether in the cloud, on-premise, or at the edge, the next challenge is making data usable, consistent, and accessible across systems. That’s where ETL comes in.
Extract, Transform, and Load
Extract, Transform, and Load (ETL) is a process that takes the data from the source systems (plant equipment, logistic systems, order entry systems, etc.) and transforms that data to be consistent across all the platforms. In last week’s blog, we discussed how you might store some temperatures in Fahrenheit and some in Celsius. During the transformation process, the data would be converted to Fahrenheit or Celsius or both, depending on its intended use in analytics. After all the transformations have occurred, the data is loaded into the database.
When ETL first started, it was generally handwritten SQL (Structured Query Language, which most products use to talk to relational databases) or generated through tools. Over time, modern approaches have emerged to improve flexibility, efficiency, and scalability. The ETL process became more difficult as it grew in size. This has led to more modern approaches to emerge, driven by cloud platforms, AI/ML, and new architectures. Let us explore how these modern approaches are reshaping the way data moves and transforms within industrial environments.
As you decide what is the best approach for your organization, you need to consider the cost of the added CPU, memory, network bandwidth, and disk.
Data Lake Approach
We discussed the data lake approach in last week’s blog. Here is how ETL is approached within the data lake.
- Extract – data is extracted from their sources and stored in its raw format in the data lake.
- Transform – Transformation is deferred until it is needed by the user community. Then the user community communicates what transformations they want.
- Load – it is already loaded in its’ raw format for future use.
Data lakes offer flexible, cost-effective storage for large volumes of industrial data in various formats. They are ideal for scaling across sensors, machines, and systems. However, they can introduce data quality challenges, make management more complex, and often deliver slower query performance than structured data warehouses.

Cloud-based ETL
Cloud-based ETL uses cloud services (AWS Glue, Google Cloud Dataflow, Azure Data Factory) to perform the ETL operations that would normally be done on-site. Cloud-based ETL offers cost-effective scalability, reduced dependence on on-premise infrastructure, and access to a wide range of data sources and advanced transformation tools. It is ideal for organizations with distributed plants, equipment, and IIoT systems. However, it relies on stable connectivity, and latency or security concerns may limit its suitability for real-time control or highly regulated industrial environments.
Extract, Load, and Transform (ELT)
While cloud-based ETL centralizes transformation in the cloud, another modern variation shifts where the transformation happens altogether. Extract, Load, and Transform (ELT) flips the traditional ETL process by first loading raw data into the target database and then performing transformations within that system.
This method is especially effective when using powerful cloud or industrial data platforms, as it minimizes data movement and leverages in-database processing for faster performance. However, it often requires a more robust DBMS and careful planning to maintain consistency and scalability across industrial applications.
Microservices Architecture
The microservices architect breaks down the process into small, independent services that can be deployed and scaled independently. For example, you may break down the ETL processes into three microservices – Extract services, transformation services, and load services. The Extract services can be broken into services that are responsible for a specific data source, all running in parallel and independently.
Benefits
Scalability: Each service can be scaled separately without affecting other services, and the resources (CPU, memory) can be allocated based on the needs of the specific microservice.
Monitoring and Logging: Since the microservices are broken into smaller components, it is easier to monitor all of the services in real-time and receive alerts. With logging turned on in the microservices, you can gather all of the logs and analyze them together to increase the performance and efficiency of each microservice as it applies within the full process.
Resilience: Using microservices allows for more fault tolerance in the process. If a transformation service fails, only that process is impacted, not the whole ETL process. With the ability to run multiple instances of a service, there is high availability and fault tolerance built into the process.
Technology Diversity: Different services can use different languages and frameworks that best suit their needs. For example, you might use Python for transformation services and Java for extraction services.
Considerations
Increased Complexity: The overhead of managing multiple microservices might be significant. The initial setup and ongoing support need to be considered.
Resource Intensive: You might need more resources (CPU, memory, network) since there is a lot of inter-service communication.
Data Consistency Issues: Maintaining data consistency across distributed services can be difficult, especially within transformation services and load services. This might lead some organizations to acknowledge that the data will eventually be consistent, which can lead to temporary inconsistencies in the data.
Cost Implications: There will be additional infrastructure required to support microservices. A trade-off should be considered based on cost versus the ability to access the data more quickly for analysis.
Real-time ETL
Real-time ETL processes the data immediately to allow the data to be used by the user community faster and as close to real-time as possible. This architecture generally uses tools that provide a mechanism to pipe the data (example: Apache Kafka) into a computational engine (example: Apache Storm) to retrieve and transform the data.
Benefits
Data Freshness: Being able to gain insights quickly by having the data available as soon as it is generated allows the user community to make decisions based on the current data available.
Competitive Advantage: By getting the data in real-time, it provides the ability to react faster to market changes and customer needs. This can allow organizations to use innovative use cases like real-time personalization, dynamic pricing, and predictive maintenance.
Event-driven Processing: Allows systems to react immediately to events as they occur. This can be used to automate actions based on real-time data, such as alerts and notifications, enabling quick adaptation to changing conditions.
Considerations
Data Quality Issues: Real-time data may be inconsistent or incomplete, leading to potential data quality issues. Dealing with errors and accuracy in real-time can be more difficult than batch processing.
Complexity and Resource Intensive: The system design for real-time systems is more complex, and integrating real-time data streams with existing systems can be challenging. Along with the complexity, real-time requires significant computational resources and network bandwidth to handle the continuous flow of data. The debugging and monitoring become more complex due to the continual flow of data.
Cost Implications: The infrastructure required to run real-time ETL can be expensive. The cost of continuous monitoring and maintenance should also be considered.
AI and Machine Learning Integration
AI adoption in ETL is gaining momentum as industries seek greater efficiency, automation, and the ability to manage increasingly complex data environments. While still in the early stages of universal adoption, industry analysts cite AI as a major growth driver for the ETL market.
AI enhances ETL by:
– Automating data extraction, reducing manual entry and errors.
– Improving data quality through anomaly detection and automated cleansing.
– Optimizing transformations for faster, smarter processing.
– Enabling predictive analytics directly within transformed datasets.
– Creating self-repairing pipelines that detect and fix workflow issues automatically.
Challenges remain, including high implementation costs, a steep learning curve, potential bias in AI models, data privacy concerns, and the ongoing need for high-quality data and maintenance.
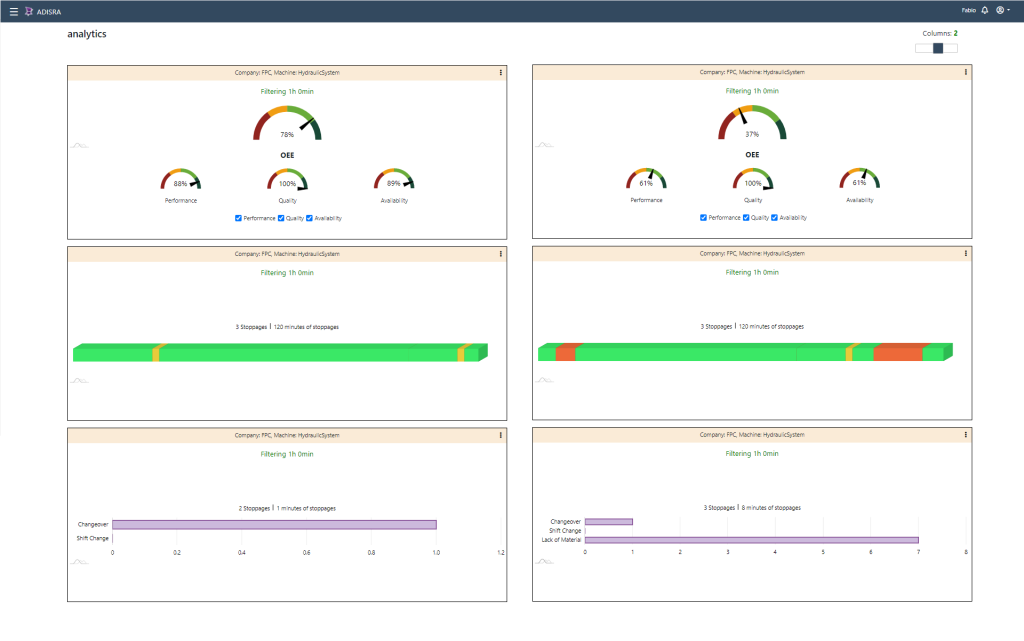
Bringing It All Together with ADISRA
The true value of ETL lies in pairing these various architectures and methodologies with platforms designed for industrial automation. ADISRA SmartView, an HMI/SCADA package, InsightView, an OEE & Advanced Analytics, and KnowledgeView, a predictive maintenance platform, integrate with a wide range of databases and data architectures, enabling seamless extraction, transformation, and loading of data from machines, sensors, and enterprise systems. By combining ETL best practices with AI-driven analytics, ADISRA’s solutions turn raw industrial data into real-time visualizations, performance metrics, and predictive insights, helping manufacturers improve efficiency, quality, and uptime across their operations.
Start building intelligent industrial automation solutions today with ADISRA SmartView; download it here.
Have a project in mind? Let us talk. Click this link to request a personalized demonstration with our team.
Need a temporary account for InsightView and KnowledgeView. Request the account at info@adisra.com.
Have an account for InsightView and KnonwledgeView? Access the demo here.
Conclusion
As industrial environments become more complex and data-driven, modern ETL strategies play a crucial role in managing and transforming large volumes of data. By adopting technologies such as AI, machine learning, cloud-based ETL, data lakes, microservices, and more, businesses can achieve higher efficiency, scalability, and data-driven decision-making. These innovations not only tackle the growing complexity of industrial data but also help organizations stay competitive in a fast-evolving market.
Looking ahead, next week’s blog will dive into Modern Approaches: Data Fabric, Data Mesh, and Unified Namespace (UNS). We hope you’re enjoying this series, and as our world becomes increasingly data-intensive, the importance of these concepts will continue to grow.
Stay tuned for next week’s blog!
ADISRA Webinar Series:
Just a friendly reminder that the ADISRA webinar series will be taking a break this August. We will be back with fresh, exciting webinars on September 25th at 9:30 am CDT. We look forward to seeing you then!

Chuck Kelley is a consultant, computer architect, and internationally recognized expert in data technology. With over 40 years of experience, he has played a key role in designing and implementing operational systems, data stores, data warehouses, and data lakes. Chuck is the co-author of Rdb/VMS: Developing the Data Warehouse with Bill Inmon and has contributed to four books on data warehousing. His insights have been featured in numerous industry publications, where he shares his expertise on data architecture and enterprise data strategies. Chuck’s passion lies in ensuring that the right data is delivered in the right format to the right person at the right time
ADISRA®, ADISRA’S logo, InsightView®, and KnowledgeView® are registered trademarks of ADISRA, LLC. © 2025
ADISRA, LLC. All Rights Reserved