
A recent discussion on data cleansing reinforced a simple truth: AI cannot reason over data that humans cannot trust.
Data is now the most valuable asset in digital transformation. Yet despite the heavy focus on algorithms and models, the reality is clear: AI success, and most industrial automation success, is not a model problem. It is a data problem.
According to Gartner, 57% of organizations acknowledge that their data is not AI-ready. Their research consistently shows that the real barrier to scaling enterprise AI is not model sophistication, but data readiness. Fragmented systems, inconsistent definitions, and unclear ownership continue to prevent organizations from unlocking AI’s full transformative potential.
AI Generated
Disconnected Data, Disconnected Decisions
Data fragmentation occurs when an organization’s information is spread across disconnected systems, applications, cloud platforms, and on-premises environments, preventing a unified view of operations. I once heard it described this way: organizational data can look like toys scattered across a two-year-old’s bedroom, everywhere, but difficult to make sense of.
The result is the creation of “data islands,” where critical information remains isolated, hard to access, and even harder to govern. In this fragmented state, data loses its effectiveness, limiting its value for AI, analytics, and informed decision-making.
Fragmentation also leads to inconsistent metrics, multiple versions of the truth, and a growing reliance on manual processes to piece information together. These challenges extend beyond data management into business planning and decision-making, ultimately slowing operational efficiency, reducing productivity, and stalling innovation initiatives.
AI Generated
Why Data Fragmentation Is Amplified in Industrial Automation
Recent research highlights just how significant this issue has become. According to Modern Data 101 in The Modern Data Report 2026: The Data Activation Gap, nearly 70% of organizations say their data is not clean or trustworthy enough for AI, and 65% report that their data lacks the clarity and business context required to be useful.
In industrial automation, the challenge is even more pronounced. Critical operational and business data is dispersed across a wide range of disconnected systems, including PLCs (Programmable Logic Controllers), SCADA systems, MES (Manufacturing Execution Systems), ERP platforms, spreadsheets, and a mix of cloud and on-premises databases. This complexity makes it exceptionally difficult to establish a unified, reliable view of operations.
Addressing this challenge requires more than just technology. While strategies such as data integration, consolidation, governance, and modern architectures like data fabric are essential, they are not sufficient on their own. Organizations must also adopt a new mindset, treating data as a strategic asset and supporting it with clear ownership, standardized processes, and cross-functional collaboration.
Data fragmentation does not occur overnight. It is the result of years of organic growth, evolving systems, and disconnected decision-making across both operational and business environments.
AI Generated
Several core factors contribute to this reality:
– Legacy infrastructure continues to limit connectivity, as older equipment was never designed to integrate with modern IT or cloud-based systems.
– The persistent IT/OT divide creates structural barriers, with factory-floor systems operating independently from enterprise IT, often using incompatible communication protocols.
– Siloed software adoption adds further complexity, as departments implement specialized tools that do not share data or align with broader organizational systems.
– Mergers and acquisitions introduce additional fragmentation, leaving organizations with a patchwork of systems that are difficult to standardize and integrate.
The result is a highly fragmented data landscape. Information is scattered, inconsistently captured, and often unreliable. Each department defines and manages its own KPIs, often through manual processes, resulting in conflicting metrics and multiple versions of the truth.
At the same time, leadership is under increasing pressure to make faster, data-driven decisions, yet lacks a unified and trustworthy view of operations. OT systems were never designed for seamless integration with IT, and already constrained IT teams are left attempting to bridge the gap with limited time and resources.
This fragmentation has direct consequences. Data may exist across multiple systems but lack consistency. In some cases, it is incomplete; in others, its quality is questionable. Without a strong and reliable data foundation, AI models struggle to produce meaningful, actionable insights.
The goal, ultimately, is to transform data into something fundamentally more useful, data that is discoverable without insider knowledge, interpretable without explanation, and trustworthy without manual validation. Most importantly, it must be actionable at machine speed rather than human pace, because that is the true promise of AI.
AI Generated
Why Data Still Is Not AI-Ready
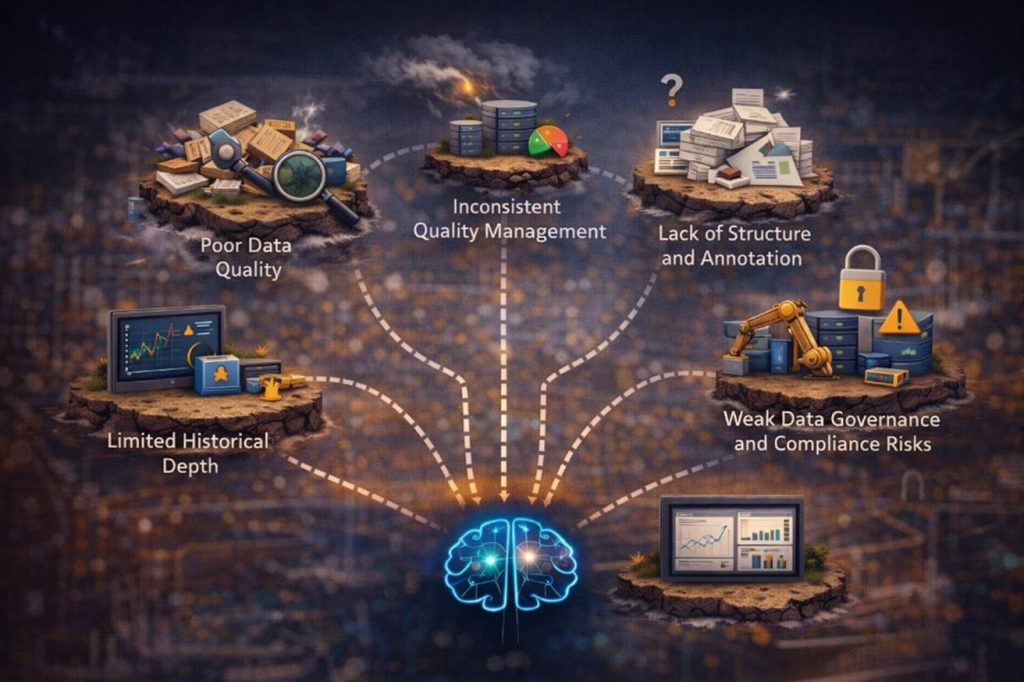
Beyond fragmentation, several additional factors prevent data from being truly AI-ready. These challenges often go unnoticed until organizations begin building models, only to discover that the underlying data cannot support them.
Poor Data Quality
Data quality remains one of the most significant barriers:
– Incomplete data: Missing critical values or fields can disrupt model training and limit accuracy.
– Inaccurate or erroneous data: Errors from manual entry or faulty sensors result in data that does not reflect real-world conditions.
– Inconsistent formats: The same information represented in different ways (e.g., “PLC” vs. “Programmable Logic Controller”) creates confusion and hinders proper interpretation.
– Outdated data: Data that no longer reflects current conditions reduces the effectiveness of predictive models.
Inconsistent Data Quality Management
Even when organizations recognize quality issues, they often lack consistent practices to address them. Effective AI requires disciplined processes such as data profiling, cleansing, validation, monitoring, and metadata management. Without these, data quality issues persist and compound over time.
Lack of Structure and Annotation
AI models rely on data that is both structured and rich in context:
– Unstructured data lacks usability: Much of enterprise data, such as PDFs, images, and emails, is not readily usable for AI without additional processing and context.
– Missing labels and annotations: Supervised models depend on labeled data to learn patterns and make accurate predictions; without it, the data’s value is significantly reduced.
– Inconsistent or noisy labeling: Poor or inconsistent annotations introduce errors, leading to unreliable models and inaccurate outcomes.
Weak Data Governance and Compliance Risks
Data must be trustworthy and traceable:
– Unclear lineage: Without visibility into where data originated or how it was prepared, validation becomes difficult.
– Security and privacy risks: Sensitive data that is not properly masked or governed cannot be safely used, especially under regulations like GDPR.
– Bias in data: Historical or unbalanced datasets can introduce bias, leading AI systems to reinforce inaccurate or unfair outcomes.
Limited Historical Depth
AI models rely on patterns over time. When organizations retain only short-term data, such as the last few years, they limit the model’s ability to learn long-term trends, seasonality, and rare events.
As organizations work to overcome these challenges, it becomes clear that preparing data for AI is not a single step—it is an architectural and operational shift. Data must be collected, contextualized, validated, and structured as close to the source as possible.
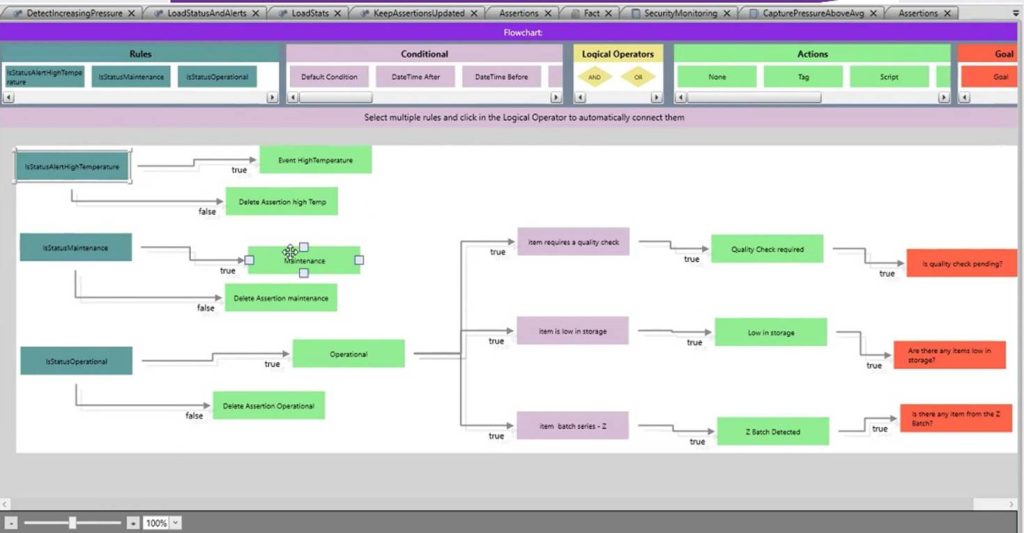
This is where modern HMI/SCADA platforms play a critical role.

ADISRA SmartView: From Data Collection to Data Intelligence
Platforms like ADISRA SmartView are designed to bridge the gap between fragmented operational data and AI-ready information. By operating at the edge, close to machines and processes, these systems capture real-time data, apply context, and structure information before it is ever sent upstream.
With capabilities such as structured data models, reusable templates, and embedded rule-based logic, ADISRA SmartView enables organizations to:
– Standardize how data is defined and collected
– Apply real-time validation and context at the source
– Reduce reliance on manual data preparation
– Establish a consistent, reliable foundation for analytics and AI
Rather than treating data preparation as a separate, downstream activity, this approach embeds intelligence directly into the operational layer, where data is created and where it matters most.
If you are ready to explore how ADISRA SmartView can help transform your data into actionable intelligence, you can download it here.
Conclusion
Algorithms do not limit the promise of AI in industrial automation; data does.
Organizations that succeed will not be those with the most advanced models, but those with the most reliable, contextualized, and accessible data. Breaking down silos, improving data quality, and embedding intelligence at the edge are no longer optional; they are foundational.
The goal is clear: data that is discoverable without insider knowledge, interpretable without explanation, and trustworthy without manual validation. Most importantly, it must be actionable at machine speed, not human pace.
AI does not begin with a model.
It begins with data, and the systems designed to make that data usable.
Interested in learning more about ADISRA SmartView? Join our next webinar on May 7th, see details below.

Design for Productivity: Advanced Features in ADISRA SmartView
Designing modern HMI/SCADA applications is no longer just about connecting data and building screens; it is about delivering scalable, intelligent systems quickly and efficiently.
In this webinar, we will explore how ADISRA SmartView’s architecture and advanced design features enable developers to significantly improve productivity and build more flexible, powerful applications.
We will begin with a high-level overview of the ADISRA SmartView architecture to help you understand the foundation that supports real-time data processing, modular design, and cross-platform deployment. From there, we’ll dive into the advanced features that allow you to design smarter, not harder.
You will learn how to:
– Reduce engineering time through reusable design strategies
– Build scalable applications using structured data models
– Implement intelligent logic without complex coding
– Make real-time changes without stopping your system
Whether you are a system integrator, OEM, or end user, this session will show you how to move beyond traditional development approaches to build high-performance, maintainable applications with speed and confidence.
ADISRA’s webinar is scheduled for May 7, 2026
Global Time Zones – Start Time:
7:30 AM PDT 9:30 AM CDT (Austin, Texas) 10:30 AM EDT/COT 2:30 PM UTC (Coordinated Universal Time) 4:30 PM CEST 5:30 PM EEST/SAST 9:30 PM WIB 10:30 PM SGT
You can register for the webinar here.
ADISRA®, ADISRA’S logo, InsightView®, and KnowledgeView® are registered trademarks of ADISRA, LLC.
© 2026 ADISRA, LLC. All Rights Reserved.