By Chuck Kelley & Marcia Gadbois

Continuing our journey into modern data management architectures, this week’s blog takes a closer look at five key approaches shaping how organizations handle information today: data fabric, data mesh, event-driven architecture, stream processing, and unified namespace.
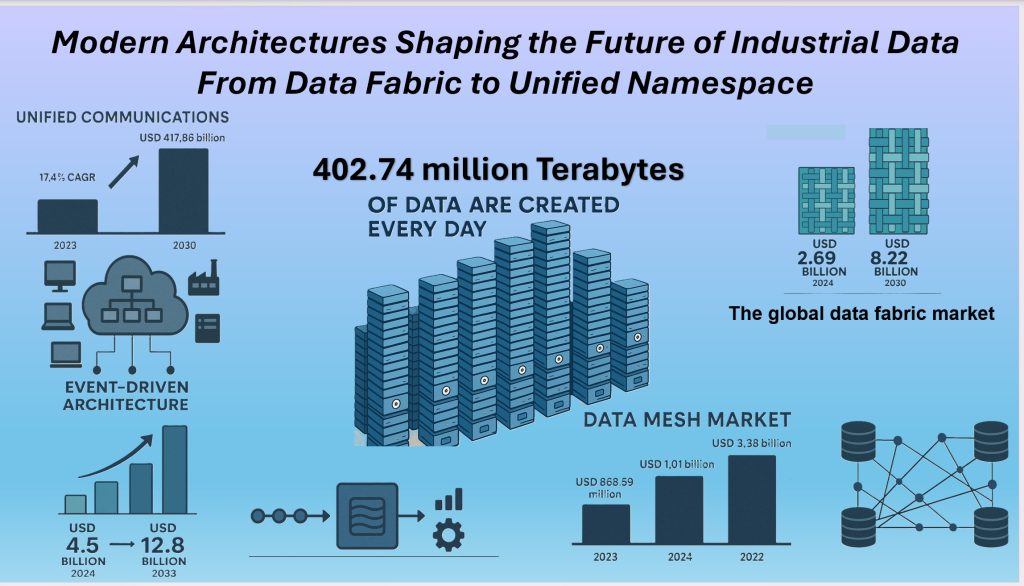
In our previous post, Foundation of Industrial Data: Architectures, we noted that an astounding 402.74 million terabytes of data are created every day, with a significant share coming from industrial automation. Managing this enormous and ever-growing volume of data requires more than just traditional centralized systems. It demands agility, compliance, and real-time insight.
As data volumes surge and diversify across platforms, modern architectures are stepping in to bridge the gap, and their adoption is driving rapid market growth. The global data fabric market was valued at USD 2.69 billion in 2024 and is expected to reach USD 8.22 billion by 2030 (MarkNtel Advisor). The event stream processing market, a core enabler of event-driven architecture, is projected to grow from USD 4.5 billion in 2024 to USD 12.8 billion by 2033, with a 12.5% CAGR from 2026 to 2033 (Lexus Industry Insights). The data mesh market was valued at USD 868.59 million in 2023 and is anticipated to expand from USD 1.01 billion in 2024 to USD 3.38 billion by 2032, reflecting a 16.3% CAGR over the forecast period.
While specific market size data for unified namespace (UNS) is limited, it is closely tied to the broader Unified Communications (UC) market, which was valued at USD 136.11 billion in 2023 and is projected to reach USD 417.86 billion by 2030, growing at a 17.4% CAGR. This surge reflects growing adoption of scalable, decentralized, and real-time data solutions across industries.
In this blog, we’ll explore how these five approaches help organizations improve data access, boost agility, and unlock real-time capabilities. We’ll also examine the pros and cons of each architecture, equipping you with the insights needed to design a corporate data strategy that supports faster, more informed decision-making.
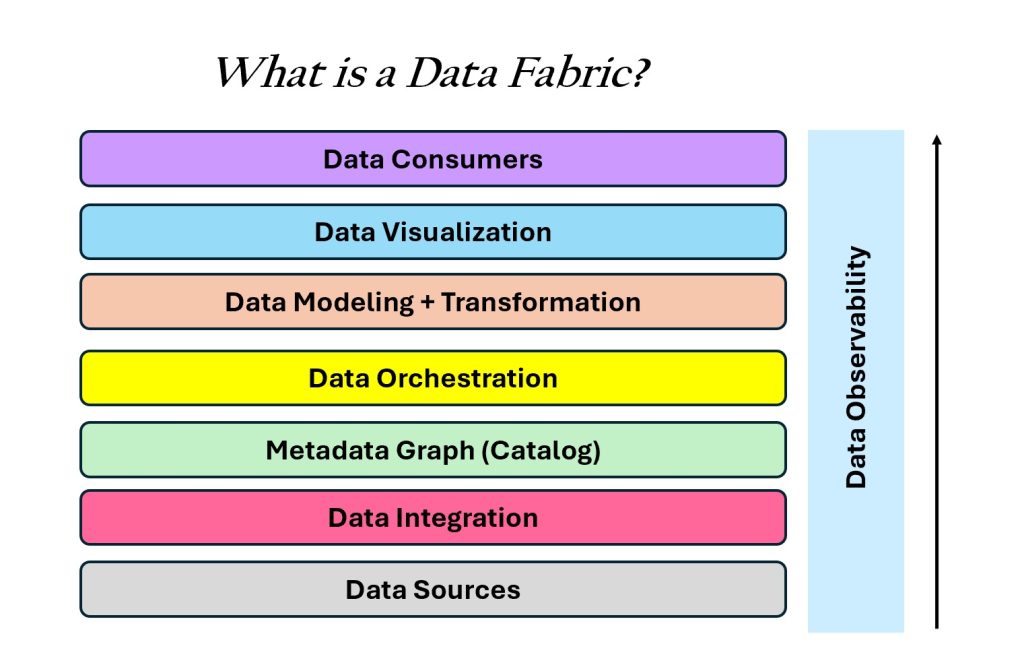
Data Fabric
Data fabric architecture operates around the loosely coupling of data in different platforms. It breaks the platform into multiple domains, and each domain builds out what it needs for its user community. Data fabric provides a single view of all data across the organization by integrating various data sources and enabling seamless access and processing. Like data governance, this approach supports ownership of the data and collaboration across the organization.
Benefits
- Unified View of Data: Provide a single, integrated view of all the data sources
- Centralized Management: Management and governance are done centrally
- Performance: Optimization of the data can provide greater and faster access
- Interoperability: Integrates various sources and formats
Considerations
- Centralization: Can lead to bottlenecks and dependency on a central data team
- Cost: May require significant costs in infrastructure, even if you are working on a cloud platform.
- Potential for data silos: Even with all the integration, data silos can still occur
While data fabric centralizes management to create a unified, integrated view of enterprise data, data mesh takes a very different approach. Instead of relying on a single, centrally managed architecture, data mesh embraces decentralization, distributing data ownership to domain-specific teams. This shift empowers those closest to the data to manage, govern, and innovate within their own areas, while still adhering to shared standards and governance across the organization.
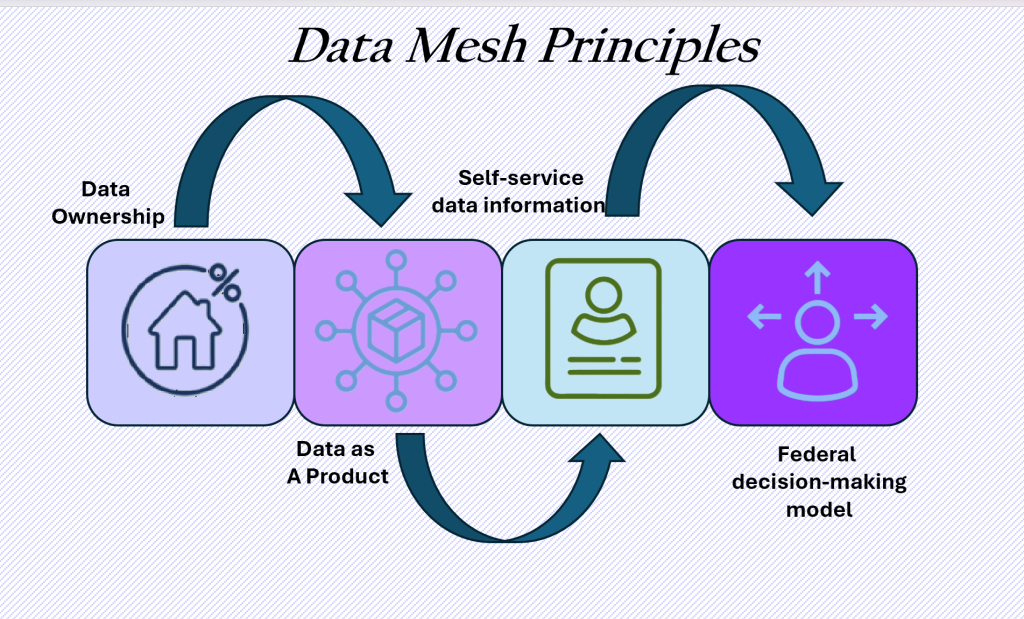
Data Mesh
Data mesh is an architecture that breaks the data down into four groups of responsibility. They are:
- Domain Ownership: Who is responsible for the data?
- Data as a Product: What does the user community need to do their job?
- Self-serve Data Infrastructure Platform: A set of domain tools to allow teams to build and maintain their data product.
- Federated Governance: Creating data policies that adhere to the Data Governance Teams’ rules and regulations
Benefits
- Data Ownership: Each domain owns its data. This should bring better data quality.
- Scalability: Since the data is owned at a single domain, the data should scale by adding more domains.
- Flexibility: Allows for optimization within each domain.
- Decentralization: Distributes responsibility to multiple teams, reducing dependency on the central data team.
Considerations
- Data Governance: Maintaining data governance across domains will be challenging. It may tend to create more data silos.
- Integration overhead: Having seamless integration between domains is very complex.
- Complexity: There will be significant organizational change that may be a challenge to implement effectively.
Both data mesh and data fabric aim to improve data management and access, but they do so in different ways:
- Data Mesh: Emphasizes domain ownership and collaboration, making it ideal for organizations looking to decentralize data management and improve data quality.
- Data Fabric: Focuses on providing a unified view of data, which is beneficial for organizations needing a centralized approach to data access and processing.
Choosing one of these approaches depends on your organizational structure, culture, and specific needs. A data mesh might be more suitable for organizations that prefer a distributed structure and require domain-specific data ownership, while a data fabric might be more suitable for organizations that require a centralized approach to data management.
While data fabric and data mesh focus on how data is organized, stored, and governed across an organization, event-driven architecture shifts the focus to how data moves and reacts in real time. Instead of waiting for scheduled updates or manual queries, event-driven systems respond instantly to changes, whether triggered by user actions, sensor inputs, or system-generated alerts. This approach transforms data from something static into a continuous, actionable stream, enabling organizations to react faster and more intelligently to what’s happening right now.
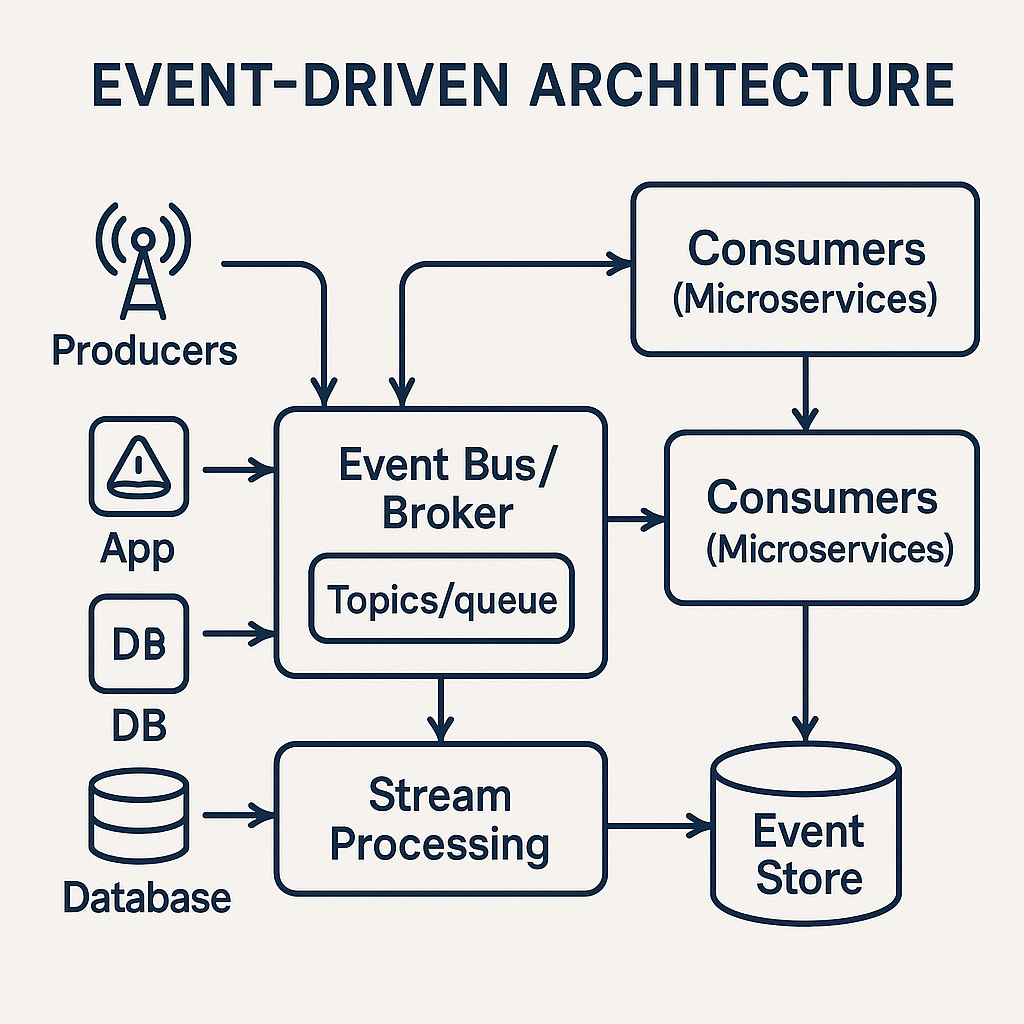
Event-driven Architecture
Event-driven architecture is exactly what you would expect. Events (actions from users, data from another program, sensor readings) drive the flow of the application. Rather than relying on a traditional request–response model or scheduled data processing, EDA enables systems to detect, process, and react to events in real time.
For example, if a fire were detected on a production machine, the event could automatically trigger a sequence of responses: halting the production line, activating safety systems, and notifying emergency personnel. Each of these actions is initiated by the event itself, allowing for rapid, automated responses without manual intervention.
This is useful if you use microservice architecture and distributed systems where components interact asynchronously.
Some key characteristics of event-driven architecture are:
- Asynchronous Processing: Not having to wait for a response before moving on to the next task.
- Scalability: Allowing increased loads by adding more instances of components
- Resilience: They continue to process other events even if one fails
- Message Brokers: Used to communicate between components. Examples of message brokers include Apache Kafka, RabbitMQ, and Amazon SQS
Benefits
- Real-Time Processing: Allows for immediate reaction to events in real-time. It is useful when you require instant feedback (fraud detection, industrial automation failure, and maintenance).
- Flexibility: New components can be added or removed without affecting other components. The ability to dynamically adjust or extend systems is another benefit.
- Resilience: Decoupling the processing can improve fault isolation, thereby reducing overall failure of the system. In some cases, the events can be retried in case of errors. Because of the modularity of the processing, you can develop, test, and deploy components independently. Since the components are decoupled, you can scale horizontally, allowing events to be processed in parallel.
Considerations
- Complexity: Event-driven processing is complex, requiring careful design, coordination, and robust event management and error handling.
- Event Ordering: In some cases, events need to be ordered correctly. This can be challenging in distributed systems.
- Performance Overhead: There is an overhead on the system, especially with high event volumes. You need to be careful when optimizing the flow of the events to balance performance and resource usage.
While event-driven architecture focuses on detecting and responding to individual events as they occur, stream processing takes this concept a step further by continuously ingesting and analyzing data in motion. Instead of reacting to discrete events in isolation, stream processing works with an ongoing flow of event data, enabling patterns, trends, and insights to be identified in real time.
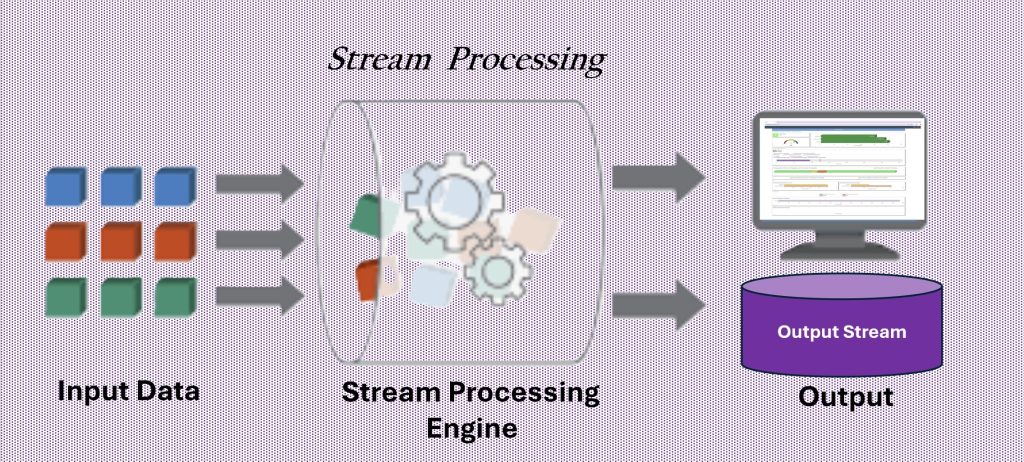
Stream Processing
Stream processing is a data processing approach that continuously ingests, processes, and analyzes data as it is generated. Unlike traditional batch processing, which handles data in fixed intervals, stream processing operates in real time, enabling immediate insights and actions.
While it shares similarities with event-driven architecture, the key distinction is scope: event-driven systems react to specific events, while stream processing manages a continuous flow of data, often combining and analyzing multiple event streams at once. This allows organizations to detect patterns, monitor trends, and respond to emerging conditions instantly.
Example: In industrial automation, stream processing can be used to monitor sensor data from multiple machines simultaneously. If vibration and temperature readings exceed defined thresholds, the system can trigger alerts, initiate maintenance workflows, and update dashboards, all without delay.
Another example is that if a local Supervisory Control and Data Acquisition (SCADA) device is capturing temperature, that temperature is being stored and sent as a stream to another application. Event-driven processing might be used if a local SCADA device is capturing temperature, but it is only sent to another application if the temperature is within a certain range of the previous temperature sent.
Benefits
- Immediate Insights: Provides real-time analysis and insights so that the decision makers can be productive. Applications that can use instant feedback include fraud detection and preventive maintenance.
- Latency Reduction: Minimizes the latency between when the data is captured and the processing of that data downstream. This enables near-instant response to data changes or anomalies. This is done by scaling the streams horizontally to handle large volumes of data.
- Resource Efficiency: By processing the data as it arrives, you reduce the need for batch processing and allow resources to be utilized more efficiently, avoiding idle time.
- Adaptability: As data patterns and requirements change, stream processing can adapt quickly by supporting dynamic adjustments to logic processing.
Considerations
- Complexity: Stream processing can be complex, requiring very specialized tools and expertise. Careful design is required to deal with real-time constraints and fault tolerance.
- Resource Intensive: Significant computing power, memory, and network bandwidth may be required. Optimization to balance performance and resources will be required.
- Fault Tolerance: Dealing with data integrity and availability when failures occur can be challenging. Robust mechanisms are required for recovery and reprocessing of the data.
While both stream processing and event-driven processing focus on real-time handling of data and events, they differ in their focus, architecture, and use cases. Stream processing is ideal for applications requiring continuous, real-time analysis of data streams, while event-driven processing is suited for applications that need to react to discrete events and trigger actions or workflows. Understanding these differences can help in choosing the right approach for specific use cases and requirements.
In many modern systems, the two approaches go hand in hand: EDA triggers actions when events occur, while stream processing aggregates, enriches, and analyzes those events as part of a continuous data pipeline. This combination is particularly powerful in scenarios like predictive maintenance, fraud detection, industrial monitoring, and IoT analytics, where both immediate reaction and ongoing insight are essential.
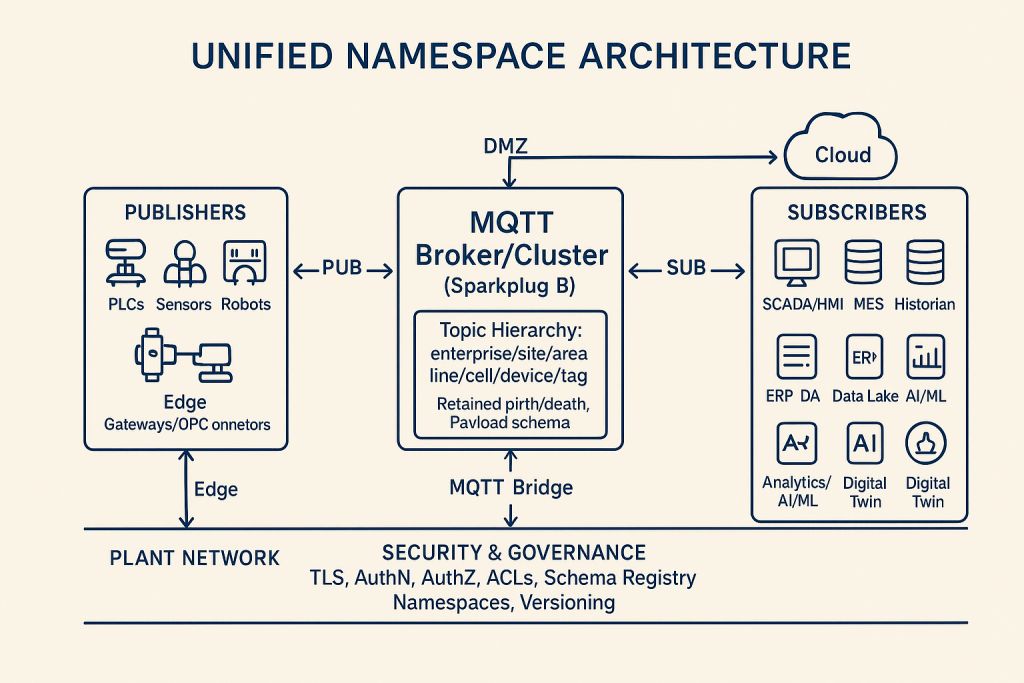
Unifed Namespace
A Unified Namespace (UNS) in industrial automation is a centralized, standardized data model that brings together information from disparate systems across an organization, creating a single source for real-time data. It has gained significant traction with the rise of the Industrial Internet of Things (IIoT) and the adoption of Industry 4.0 strategies.
Think of UNS as a universal language for all your industrial data, enabling devices, sensors, and systems, regardless of manufacturer or protocol, to share information seamlessly and in real time.
Unlike traditional industrial data architecture, which often follows the hierarchical ISA-95 pyramid model (ANSI/ISA-95 or IEC 62264), UNS is based on event-driven architecture (EDA) principles. It can be implemented using the ISA-95 equipment model (Part 2) for a standardized hierarchy or adapted to fit a company’s unique operational structure.
Instead of sending data up the chain for storage and later review, a UNS shares live, organized data from different parts of the business in real time. It works like a hub-and-spoke system, where all systems can publish and subscribe to the same information, so everyone is working with the most up-to-date view of operations.
Benefits
- Eliminates Data Silos: Consolidates diverse sources into a single, accessible structure.
- Improved Collaboration: Establishes a shared data language across teams and departments.
- Enhanced Accessibility: Delivers organization-wide, real-time data for faster problem-solving and predictive maintenance.
- Scalability: Expands easily to handle more data sources and complexity.
- Reduced Complexity: Simplifies architecture by removing redundant integrations.
Considerations
- Security Risks: Sensitive data must be protected against unauthorized access.
- Implementation Complexity: Requires thorough planning, naming standards, and integration work.
- Potential Overload: Poorly managed UNS structures can become cluttered with excessive data.
- Custom Development: UNS is not a plug-and-play product and must be tailored to each use case.
- Management Commitment: Success depends on leadership prioritization and resource allocation.
The key components of a Unified Namespace architecture include:
- Data Sources: Systems and devices that generate data, such as PLCs, sensors, and SCADA software like ADISRA SmartView.
- MQTT Broker: A central messaging hub that uses the publish–subscribe model to organize data into a hierarchical topic structure within the UNS.
- Data Modeling & Contextualization: Defining the structure and meaning of data within the UNS to ensure it is standardized and usable across all connected systems.
- Data Consumers: Applications and users that access and use UNS data, including SCADA/HMI packages like ADISRA SmartView and analytics platforms like InsightView and KnowledgeView.
While stream processing focuses on the movement and analysis of data in real time, a unified namespace (UNS) addresses how and where that data is organized for access across the enterprise. In many industrial environments, even the most advanced real-time systems can become fragmented if each application or device manages its own data independently. A unified namespace solves this by creating a single, structured, and centralized environment where all operational and business data is published and can be subscribed to by any authorized system.
This approach not only eliminates the complexity of point-to-point integrations but also ensures that all stakeholders, from plant floor operators to corporate decision-makers, are working from the same, most up-to-date information. In essence, UNS acts as the “single source of truth” that stream processing and event-driven architectures can feed into and leverage.
Start building intelligent industrial automation solutions today with ADISRA SmartView; download it here.
Have a project in mind? Let us talk. Click this link to request a personalized demonstration with our team.
Need a temporary account for InsightView, and KnowledgeView. Request the account at info@adisra.com
If you have a temporary account, you can access InsightView and KnowledgeView here.
Conclusion
From the centralized integration of data fabric to the domain-driven empowerment of data mesh, from the instant responsiveness of event-driven architecture to the continuous intelligence of stream processing, and finally, to the shared real-time visibility enabled by a unified namespace, each of these modern data management approaches offers distinct strengths and trade-offs.
No single architecture is a one-size-fits-all solution. The right choice depends on your organization’s goals, structure, technical capabilities, and operational needs. In many cases, a hybrid approach, combining elements from multiple architectures, can deliver the best balance of agility, governance, and scalability.
As industrial data volumes continue to explode, organizations that embrace the right architecture will be better positioned to break down silos, improve collaboration, and act on insights in real time. Whether your path leans toward centralized control, decentralized ownership, real-time event handling, continuous data streams, or a unified operational view, the end goal remains the same: turning data into actionable intelligence that drives smarter, faster decisions.
In our next and final post in this series, we’ll explore the legal, security, and compliance dimensions of data governance and context – covering regulations, privacy, access control, and breach preparedness – to ensure your data strategy is both effective and defensible.
ADISRA®, ADISRA’s logo, InsightView®, and KnowledgeView® are registered trademarks of ADISRA, LLC.
© 2025 ADISRA, LLC. All Rights Reserved.