
By Chuck Kelley & Marcia Gadbois
Every day, approximately 402.74 million terabytes of data are generated, much of it driven by industrial automation. What was once considered an emerging trend, the Industrial Internet of Things (IIoT), has now become the foundation of modern manufacturing. Also known as Industry 4.0 or smart manufacturing, IIoT refers to the digital transformation of operations through the real-time connection of machines, devices, and systems.
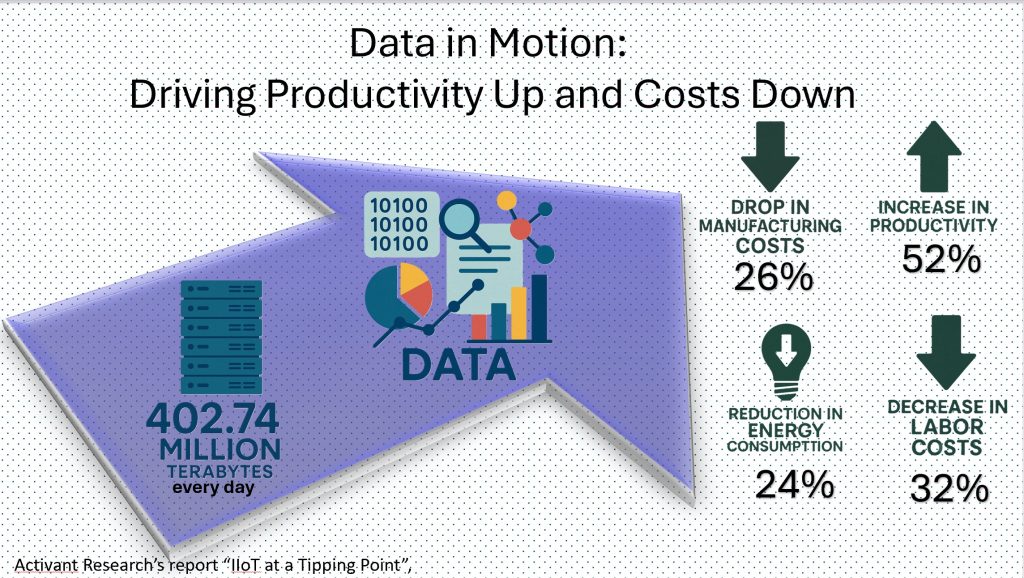
At the heart of this transformation is the ability to harness the massive volumes of data produced by industrial equipment. By leveraging this data, manufacturers gain actionable insights that enable smarter decision-making, optimized processes, and significant efficiency improvements. According to Activant Research’s report “IIoT at a Tipping Point”, companies that adopt intelligent software and IIoT solutions experience:
24% reduction in energy consumption
52% increase in productivity
32% decrease in labor costs
26% drop in manufacturing costs
These benefits collectively translate into an estimated 25% reduction in the global manufacturing sector’s cost of goods sold (COGS). As data storage becomes more affordable and internet connectivity expands, the potential for value creation through IIoT grows exponentially, further accelerating the pace of data generation.
Yet with this surge in data comes increased complexity. Traditional data architectures—such as relational databases and data warehouses—still play an important role but often struggle to keep pace with the volume, velocity, and variety of data generated by IIoT systems. To unlock the full potential of Industry 4.0, organizations must embrace modern data strategies and architectures built to support real-time, high-scale, and heterogeneous data environments.
Over the next three weeks, we’ll explore these topics in a special blog series co-written with data expert Chuck Kelley. Each post will examine the strengths and challenges of different data storage architectures:
Week 1: Core Architectures
Week 2: Modern Approaches and ETL Strategies
Week 3: Governance and Context
We invite you to follow along and hope you find this series insightful and valuable.
The Backbone of Industrial Intelligence: Core Data Architectures Explained By Chuck Kelley
In every organization, there needs to be a way to store collected data. The storing of that data can be in flat files, CODASYL databases, relational databases, document-oriented (NoSQL, XML, graph databases), time-series databases, etc.
The most important idea to remember is that you need to use the style of database that best fits the needs of the user community to access and store the data.
Let us explore storage architectures.

Flat Files
Flat files are the basic operating system (OS) files. In their basic form, your applications create a layout of what the data should look like and what each name should be, and that is stored on the disk using that information. Before databases were created, flat files were the way data was stored.
In one sense, flat files are the only way to store data. Databases use OS files to store their data and have a system (i.e., the database management system) built around how it all ties together (locking, isolation level, compression, partitioning, metadata, etc.).
There is a realization that some will find the previous paragraph an over-simplification, so let us not dwell on that.
Databases
Databases are an organized collection of data that is accessed via a database management system (DBMS). The DBMS adheres to rules on how to access and manage the data. Since all end users and applications access the data from the DBMS software, the database rules are adhered to. For example, in relational databases, it is a general principle that during a transaction, if you read a row of data, that data will not be changed until you end the transaction. You do this by “locking” the row. But since the database is just an OS file, a nefarious person could open the OS file and start writing data, and break that principle. That is why there is so much protection at the OS level to protect these files.
There are different models for databases.

CODASYL or Network Model
Before the relational database, there was the network model (CODASYL). The network model is not widely used today, but was one of the first database models to have a DBMS.
Examples of these types of databases are:
• Cullinet Integrated Database Management System (IDMS)
• Univac DMS-1100
• Digital Equipment Corporation (DEC) DBMS (bought by Oracle and renamed to Oracle Codasyl DBMS)
• Honeywell Integrated Data Store (IDS/2)
As far as I can tell, Oracle Codasyl DBMS is the only one being sold today.
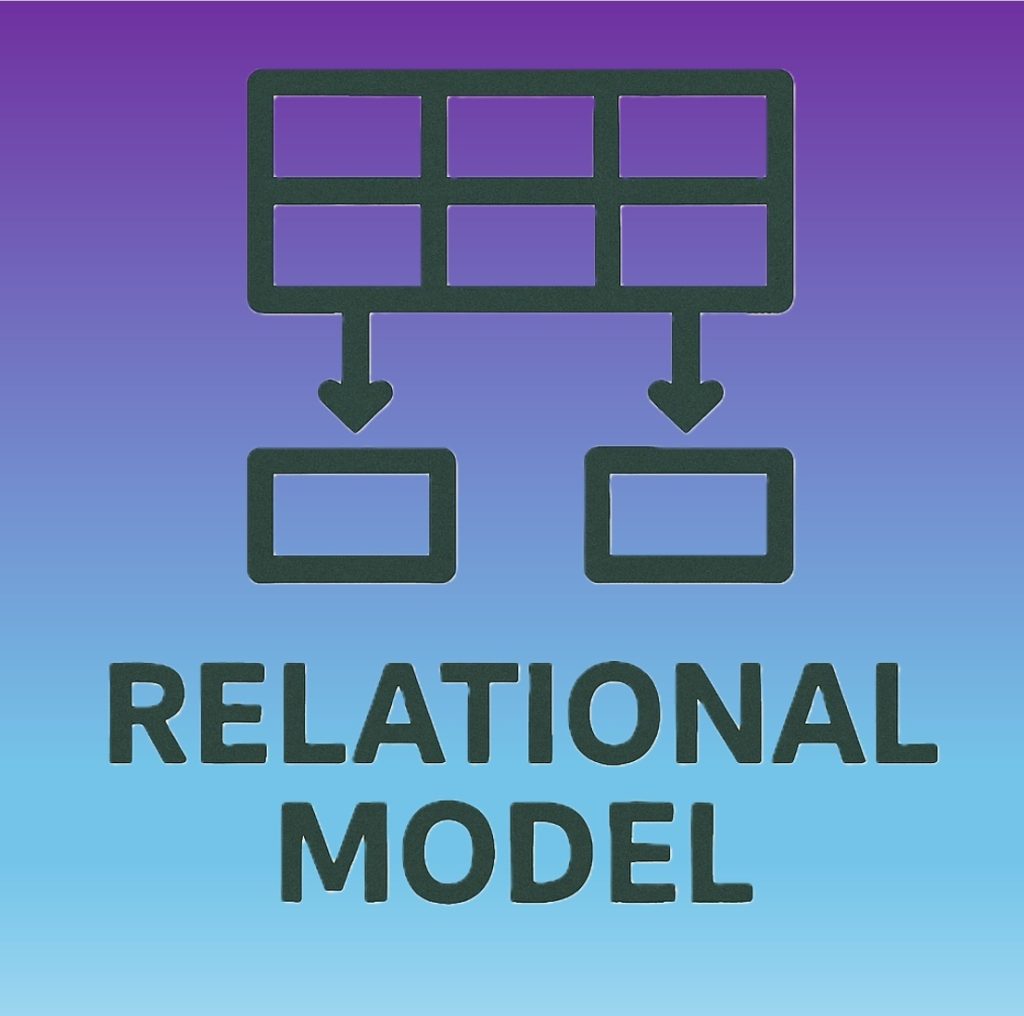
Relational Model
The relational database model is the most widely used approach for managing structured data. It was introduced by Edgar F. “Ted” Codd, a computer scientist at IBM, who proposed a new way of organizing data using tables (also known as relations). His groundbreaking work led to the development of Codd’s 12 Rules, a set of principles intended to define what qualifies as a true relational database management system (RDBMS), emphasizing consistency, data independence, and logical structure.
Relational databases primarily handle structured data, organized in rows and columns, but they also support unstructured data through special data types like BLOBs (Binary Large Objects). BLOBs are used to store large binary data such as images, videos, or multimedia files within a relational framework, although this is not their core strength.
Codd’s model revolutionized data storage and retrieval, forming the foundation for modern SQL-based systems like Oracle, MySQL, PostgreSQL, and Microsoft SQL Server.
The relational model defines data into tables (relations) made up of columns (attributes) and rows (tuples or records). The relationship between the tables is a logical connection based on data values.
In traditional industrial systems, databases were often siloed, storing a single type of data such as production orders, equipment logs, or maintenance records, with no straightforward way to integrate or correlate the information across systems for a unified operational view.
The most common model is the relational model.

Document-oriented Databases
Document-oriented databases store semi-structured data. They are known as NoSQL, XML, and, in a way, graph databases (graph databases can be separate as well from document-oriented databases).
Document-oriented databases generally store their data in key-value pairs. Examples of document-oriented databases include:
• CouchDB
• DynamoDB
• MongoDB
• Oracle NoSQL Database

Data Warehouse
The data warehouse came about because the need to analyze the data was a long and arduous process to integrate all of that data within the organization. While you could set up links between all of the databases, having all of the analytical users access the operational systems brought the operational system to a screaming halt, which is not a good thing.
The data warehouse starts with an understanding of what data means – what does the value 12.3 mean in the field temperature? Is it in Fahrenheit, Celsius (centigrade), or the Kelvin scale? What does a datetime column mean? Is it GMT, UTC, WIB, CES, SGT, SAST, MST, CDT??
In our previous blog on Data Governance, we discussed the importance of understanding the data in this way. The data warehouse started to put that importance across the whole organization, which is why the data governance was a byproduct of the data warehouse.
So that data warehouse took data from the operational databases (and spreadsheets) and combined it into a single database that had some logic to convert (or transform) the data to have the same meaning. In our example above, if one operational system stores temperature in Fahrenheit and one stores it in Celsius, then calculations were made to convert to a single, comparable scale, either Fahrenheit or Celsius. Some data warehouses store both converted temperatures so that you could use either scale without having to calculate on the fly (wasting CPU).
As expected, the data warehouse grew too large to be queried quickly. Enter the data mart.

Data Mart
The data mart is a subset of the data warehouse that was specifically created for a specific usage. Management might want to only see financial data from all of the subsidiary financial systems. They probably do not care about the temperature of some process. So that bit of information from all of the financial systems would be brought out of the data warehouse and transformed into the way the management group wanted to view the data. This would make the data faster to retrieve and present to management. Typically, these are in the form of Star Schemas or Snowflake Schemas.
It should be noted here that there are two main approaches to the data warehouse/data mart concepts: Bill Inmon and Ralph Kimball. While there are both commonalities and differences between the two approaches, a detailed comparison is beyond the scope of this blog. However, if you’re interested in a deeper dive on the topic, feel free to leave a comment and let us know. For now, think of a data warehouse as the staging area and a data mart as the presentation layer—this conceptual distinction helps illustrate how they work together.
Data Vault
Because of new laws (Sarbanes-Oxley in the US and similar measures in Europe), there was a need for complete traceability and auditability of information; the data warehouse/data mart did not quite meet that need. Data vault was a new architecture to be introduced. Data vault was used as either the data warehouse or staging area, and then used data marts as its presentation layer.
Data vault is defined in three types of data.
• Hub – domain of the organization
• Link – relationship among the Hubs
• Satellite – the descriptive attributes
The data vault is usually implemented on a relational database.
Virtual Data Warehouse
To avoid the cost and complexity of maintaining multiple copies of the same data, organizations began adopting the concept of a virtual data warehouse. This approach enables direct access to production data for reporting and analytics, eliminating the need for redundant storage while still supporting real-time insights.
Personal Perspective: Why I Have Concerns with This Approach
While the concept of a virtual data warehouse has its appeal, there are a few practical concerns that often get overlooked:
- System Load: How much extra capacity does your production system have? Many system owners already complain when the ETL (Extract, Transform, Load) process kicks in, citing noticeable slowdowns.
- Query Performance: Production environments are optimized for real-time transactions, not for running complex queries that span a decade’s worth of historical data.
- Data Retention: Does your production system even need to store 10+ years of data? In many cases, long-term historical data is better housed elsewhere.
- Processing Overhead: Do you want your production CPUs constantly converting temperature values or performing user-specific calculations on the fly?
For small businesses with limited infrastructure, this model might be sufficient. But for most mid-sized to large industrial operations, it simply does not scale well or align with performance and reliability needs.

Data Lake
As data transformation processes grew more time-consuming and the demands of modern organizations evolved, traditional data warehouses began to fall short in terms of efficiency. Challenges such as managing unstructured or semi-structured data, as well as handling the increasing velocity of incoming information, highlighted these limitations. In response, the concept of the data lake emerged, designed to store large volumes of raw data in its native format, enabling more flexible and scalable data processing.
Data lakes take the raw data in a variety of formats and store them together. While it is a fast way to take the data from operational systems and store it for analysis, there are some drawbacks. Where the data warehouse tried to transform the data (remember the temperature example above), the data lake just stored the raw data. It was up to each analyst to remember what scale the temperature was and to make the data consistent, based on the scale you wanted. The data warehouse tried to enforce data quality; the data lake did not. It was up to the analyst. Many of the benefits of the data warehouse were lost; therefore, the benefits of the data lake never materialized.

Data Lakehouse
The data lakehouse is supposed to take the best of the data warehouse and data lake to make a better analytical environment for the user community. By creating a metadata and data governance layer on top of the data lake, the user community should be able to achieve the benefits of a data warehouse, along with access to more real-time data.
This will allow for a diverse workload, including data science and machine learning,
I still have some reservations, as noted in the personal perspective above. While the intent behind this approach is valid and forward-thinking, I believe the technology hasn’t fully matured to meet the demands of most real-world industrial environments.

Time-Series Databases
There are databases specifically designed for time-series data, which are ideal for applications like tracking temperature or liquid volume in a processing plant. But do you want to store the same value every second if it hasn’t changed? For example, if the volume in a tank remains constant over a 5-hour period, recording that same value every second leads to a massive amount of redundant data.
One approach is to store only the start and end timestamps for a value, but this introduces processing overhead. You’d need to:
- Check the current value,
- Compare it with the latest value in the database,
- And if it is changed, close the previous record and insert a new one.
Doing all of this every second can be a performance bottleneck. A more efficient strategy is to monitor the current value and only write to the database when it changes, significantly reducing unnecessary writes and improving overall performance.
Time-series databases are built to understand time. So, if you query the database to find the temperature and volume of the liquid in container 3 at 10:37am on March 25, 2025, it is a straightforward query. You do not have to worry about adding where 10:37 am on March 25, 2025, is between the begin datetime and the end datetime for both temperature and volume tables. You can see that it can be complex.
In the industrial automation world, this could be quite an advantageous feature to have. Examples of time-series databases are
• eXtremeDB
• InfluxDB
• Prometheus
• TimscaleDB
It should be noted that some relational databases also have extensions to deal with time-series databases. It is best to test which approach is best for you.
Relational Databases: The Proven Backbone of Industrial Data
Relational databases have long served as a dependable method for storing and analyzing structured data, such as numbers, dates, and text, using Structured Query Language (SQL). For years, they were the go-to solution for managing business data due to their simplicity, reliability, and broad compatibility. However, as industrial data volumes have grown exponentially, traditional relational databases alone often struggle to meet modern scalability and performance demands. Even so, they remain essential for many structured data applications across industries.
While relational databases may not be the newest or flashiest technology, their enduring relevance lies in their versatility and familiarity. In professional environments, SQL continues to serve as a foundational tool for data analysis, reporting, and operational decision-making. Its widespread adoption across nearly all major database systems and its integration into many enterprise and industrial automation platforms make it indispensable.
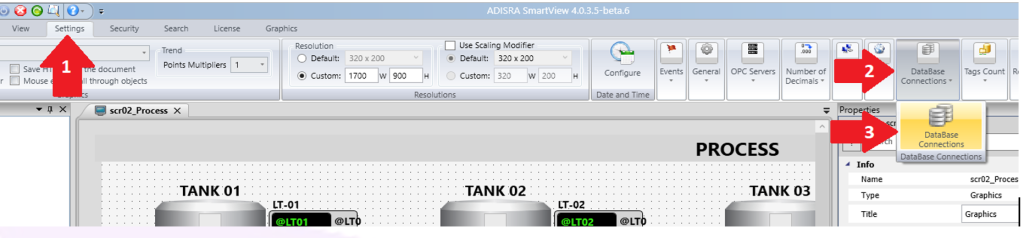
ADISRA SmartView fully supports this enduring technology by providing easy and flexible integration with popular external relational databases, including SQL Server, MySQL, PostgreSQL, SQLite3, Oracle, and Microsoft Access. Connecting ADISRA SmartView to one of these databases takes just four simple steps:
- Navigate to the top menu and click Settings → DataBase Connections → DataBase Connections.
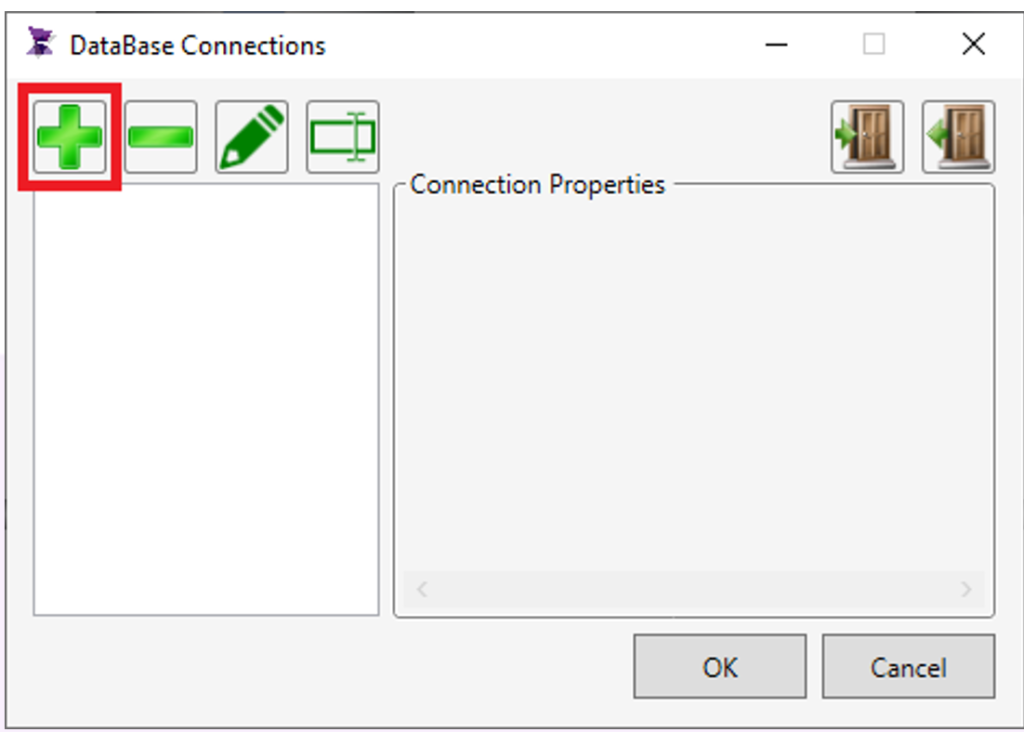
2. In the Database Connections menu, click the “+” button to create a new connection.
3. Select your Data Source (e.g., Microsoft SQL Server), then click OK.
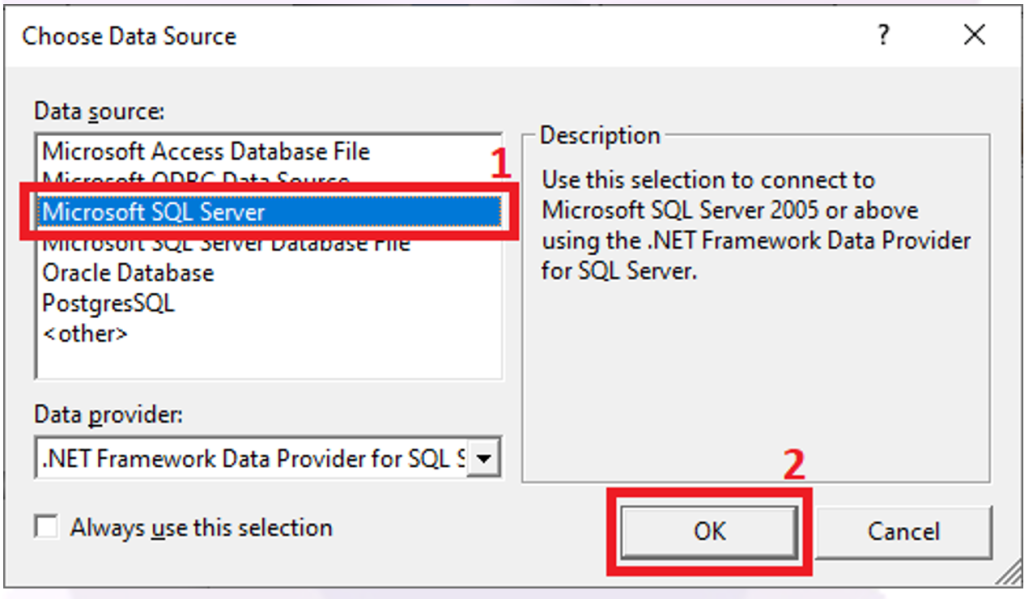
4. Fill in the required connection details—such as server name, location, and security credentials, and click Connect.
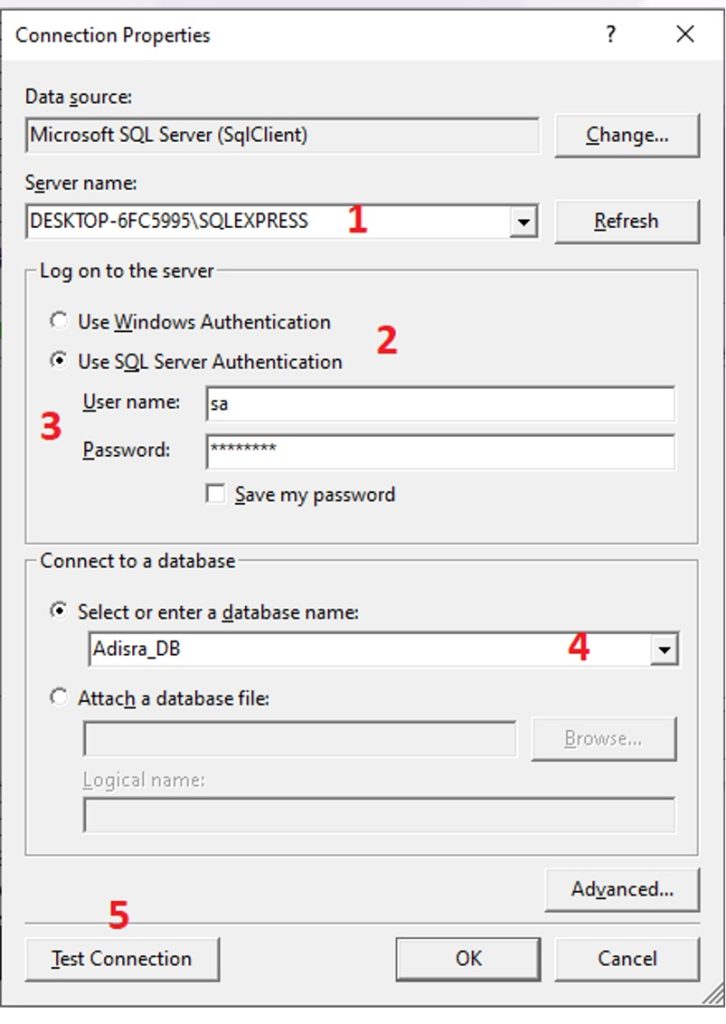
With that, you are linked to your external database and ready to harness your structured data in real time.
Despite the rise of newer architectures and platforms, relational databases continue to play a critical role in industrial automation. Their compatibility with established standards and widespread support make them a vital component of any modern data strategy. ADISRA SmartView builds on this foundation by offering seamless SQL-based connectivity, enabling users to unlock powerful insights, improve visibility, and drive smarter decisions across their operations.
Want to see it in action? Explore how easy it is to connect ADISRA SmartView to external databases with this video, this whitepaper, or this interactive demo. Do you want to try ADISRA SmartView for yourself? You can download ADISRA SmartView here.
Conclusion
As industrial operations continue to evolve under the influence of IIoT and smart manufacturing, the importance of choosing the right data architecture has never been greater. From flat files and relational databases to time-series systems and emerging models like data lakes and lakehouses, each architecture has its strengths, challenges, and place in the modern industrial landscape.
What is clear is that there is no one-size-fits-all solution. The right architecture depends on your specific needs, whether it is real-time process monitoring, long-term historical analysis, machine learning integration, or enterprise-wide visibility. Understanding the foundations of these models is the first step in building a reliable, scalable, and intelligent data infrastructure.
At ADISRA, we recognize the value of these diverse architectures and make it easier for you to integrate them into your operations. With native support for relational databases and the flexibility to evolve alongside your digital transformation journey, ADISRA SmartView empowers you to make smarter, data-driven decisions today and into the future.
Stay tuned for Part 2 of this blog series, where we will explore modern approaches and ETL strategies that help bridge legacy systems with next-generation analytics.
Try ADISRA SmartView today by downloading a trial package here.

The ADISRA Webinar Team is taking a short break during August to accommodate vacation season and back-to-school commitments. But do not worry, we will be back soon!
Save the date: Our next live webinar will be held on Thursday, September 25th at 9:30 AM CDT. (UTC -5)
Stay tuned for the upcoming topic and registration link!
In the meantime, we would love to hear from you:
– Have an idea for a future webinar?
– Want to showcase a unique application you’ve developed using ADISRA software?
Please send your suggestions to info@adisra.com. We are listening!
Please note: While the webinar series is taking a break, ADISRA is open for business throughout August.
If you need assistance with sales, support, or training, we are here and ready to help.
Thank you for being part of the ADISRA community. Enjoy your August!

Chuck Kelley is a consultant, computer architect, and internationally recognized expert in data technology. With over 40 years of experience, he has played a key role in designing and implementing operational systems, data stores, data warehouses, and data lakes. Chuck is the co-author of Rdb/VMS: Developing the Data Warehouse with Bill Inmon and has contributed to four books on data warehousing. His insights have been featured in numerous industry publications, where he shares his expertise on data architecture and enterprise data strategies. Chuck’s passion lies in ensuring that the right data is delivered in the right format to the right person at the right time
ADISRA®, ADISRA’S logo, InsightView®, and KnowledgeView® are registered trademarks of ADISRA, LLC.
© 2025 ADISRA, LLC. All Rights Reserved.